|
|
Post by Admin on Jan 12, 2024 19:21:29 GMT
Implications of subcontinental admixture for association analysis To understand the impact of subcontinental admixture in association studies and approaches to correct potential confounding, we investigated the classical association between LCT (rs4988235) and height, which has been claimed to be a false positive result due to stratification27. In addition, we evaluated the associations of rs4988235 with BMI and LDL, which were recently identified in large GWAS meta-analyses using primarily European-ancestry individuals (up to 500K samples)14,25,26. These studies either adjusted association models for genome-wide ancestry using the first 10 principal components26 or there was no evidence of adjustment for European population stratification25. Using our integrated set of European American cohorts (Supplementary Data 2), we replicated the previously reported associations between rs4988235 and height, LDL, and BMI when models were not adjusted for principal components, i.e., genome-wide ancestry (Fig. 6 and Supplementary Data 8). Different levels of adjustment for population structure (the genetic relatedness matrix, genome-wide ancestry [PCs], and/or locus-specific posterior probabilities of subcontinental European ancestry) attenuated the associations of rs4988235 with height and LDL (Fig. 6A, B and Supplementary Data 8). Importantly, when models were fully adjusted for both genome-wide and locus-specific subcontinental European ancestry, the associations of rs4988235 with height and LDL were completely eliminated, indicating that the unadjusted associations were false positives. In contrast, the association between rs4988235 and BMI remained weakly significant after adjustment for both genome-wide and locus-specific ancestry (Fig. 6C and Supplementary Data 8). Fig. 6: Forest plots showing the association between rs4988235 and multiple traits, accounting for different levels of control of population stratification. 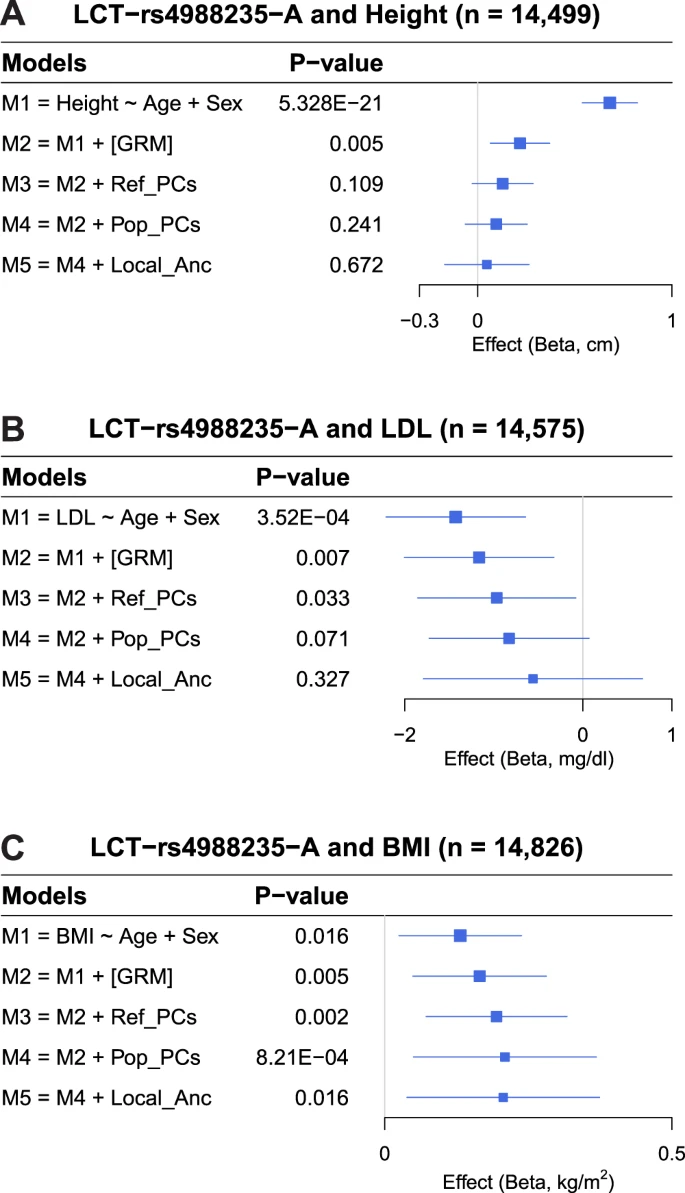 |
|
|
|
Post by Admin on Jan 14, 2024 20:11:14 GMT
We also performed cohort-specific association analysis between rs4988235 and height, LDL, and BMI, (Supplementary Data 9–11). When models were not adjusted for population stratification, the association between rs4988235 and height was significant in ARIC, CARDIA, FHS, and MESA but not in GENOA (Supplementary Data 9). The lack of association in GENOA might be explained by a small amount of ancestral heterogeneity and/or by small sample size. After adjustment for genome-wide ancestry, we observed association between rs4988235 and height in CARDIA but not in the other four cohorts. After adjustment for genome-wide and locus-specific ancestry, we observed no association between rs4988235 and height in all five European American cohorts (Supplementary Data 9). Similarly for LDL, we observed some cohort-specific associations when models were not fully corrected, and that full adjustment attenuated or eliminated significance in all cohorts (Supplementary Data 10). These results imply that full ancestry adjustment (genome-wide and locus-specific subcontinental ancestry) may facilitate correction for residual stratification and avoidance of false positives in single studies.
To evaluate if subcontinental admixture could affect associations at other genetic loci, we performed genome-wide association analysis (GWAS) of height using models unadjusted and adjusted for genome-wide and locus-specific subcontinental ancestry (Fig. S4). As with rs4988235, we found that the associations with height for SNPs that were highly differentiated within Europe29 were attenuated after adjustment for subcontinental admixture (Supplementary Data 12). Also, we identified 27 loci with signals of association with height in models unadjusted for locus-specific ancestry that were no longer statistically significant after adjustment for locus-specific ancestry (Supplementary Data 13 and Fig. S5). After interrogating the GWAS Catalog45, none of these 27 loci were previously identified as associated with height. The additional adjustment for locus-specific ancestry in models accounting for genome-wide ancestry did not show a significant impact as assessed by genomic control (Fig. S4), but did control for confounding due to population stratification at genetic loci with locus-specific ancestry effects.
It is common practice in genetic association studies to account for genome-wide ancestry using principal components derived from study-specific unsupervised analysis (population-specific PCA). Here, we tested the approach of deriving principal components from projection of target individuals onto an external reference panel (projection or supervised PCA). To evaluate the similarity between these two approaches using our European American data, we performed Mantel’s correlation test between individuals’ genetic distances computed from the top twenty principal components obtained from the unsupervised and projection approaches. We observed moderate correlation in four studies (Mantel’s rho from 0.46 to 0.53, p < 0.001), with GENOA not showing a significant correlation (Supplementary Data 14). Differences between these two PCA approaches may have led to differences in how well confounding was controlled. During testing of the association between rs4988235 and height, we observed better model fits (ΔAIC up to 12.45)46 for some cohorts when models were adjusted for projection-derived principal components compared to study-specific principal components (Supplementary Data 9). For the integrated data set, study-specific principal components yielded better model fits than projection-derived principal components (Supplementary Data 8).
Discussion
|
|
|
|
Post by Admin on Jan 17, 2024 2:39:09 GMT
The existence of subcontinental-level ancestries has been documented within Africa and Asia4,47,48,49, yet the presence of subcontinental ancestries within Europe is not well appreciated. We compiled genome-wide genotype and sequence data from geographically diverse Europeans and European Americans to investigate subcontinental-level ancestries and admixture in European-ancestry individuals. We also explore the consequences of different strategies for addressing ancestry in genetic epidemiology studies. Our study has four major results, described below.
First, we created a new reference panel of European genetic diversity by combining five genome-wide data sets35,36,37,38,39. We showed that panels based on the 1000 Genomes Project and the Human Genome Diversity Project, separate or combined, provided incomplete coverage of genetic diversity among Europeans or the European component of European Americans compared to our new reference panel. To facilitate genome-wide ancestry estimates, we provide as a research resource a reference SNP matrix of subcontinental ancestry-specific allele frequencies (https://github.com/mateushg1/CRGGH/). This resource allows for estimation of subcontinental ancestry proportions by projection analysis based on publicly available, aggregated, and non-identifiable data. The end-user does not need to access, clean, integrate, or analyze individual-level reference data. Additionally, we made available a detailed tutorial for performing ADMIXTURE and PCA projection analyses and using locus-specific ancestry posterior probabilities as covariates in GWAS analysis using PLINK 2.350.
Second, our admixture analyses yielded formal evidence that European-ancestry individuals are admixed at the subcontinental level. Moreover, our results support the occurrence of subcontinental ancestry-related assortative mating as a social factor that shaped the genetic structure of European Americans in the US51. Using multiple approaches to infer admixture, we showed that European-ancestry individuals are three-way admixed with wide variation in ancestry proportions. The demonstration that European Americans are ancestrally heterogeneous may have implications for calibrating locus-specific ancestry analysis19 with respect to the number of generations since admixture began. Most recent admixture dates estimated for European Americans corresponded to the large-scale Migration Period in Europe (300–800 AD)52, and were consistent with gene flow after the end of Roman Empire described in ancient DNA studies of the Viking Age11 and Anglo-Saxon migrations12. A limitation of our study is that current methods for dating admixture have a limit of resolution of approximately 100 generations and tend to be biased toward more recent admixture events. Another limitation of our study is a lack of ancestrally homogeneous reference populations or individuals corresponding to the Southeast European ancestry component.
Previous work has described projection analyses of ancient DNA samples in terms of present-day ancestries53. Southeastern European ancestry mainly represents descent from early Neolithic farmers from Anatolia who carried predominantly Y chromosome haplogroup G2a. Southwestern European ancestry mainly represents descent from Early to Middle Bronze Age southern steppe peoples (north and east of the Black Sea) who carried predominantly Y chromosome haplogroup R1b. Northern European ancestry mainly represents descent from Late Bronze Age northern steppe peoples (north and east of the Caspian Sea) who carried predominantly Y chromosome haplogroup R1a. Other ancestries not of European origin, such as Arabian, North African, and North Asian ancestries, have contributed to lesser extents to present-day Europe. Additionally, we have reconstructed the phylogeny of present-day ancestries47. One key inference from that reconstruction is that the ancestry reflected in early Neolithic farmers from Anatolia is likely the most recent common ancestor of present-day Southwestern European and Southeastern European as well as Arabian and North African ancestries.
Third, studies of European-ancestry individuals have reported that genetic variants, principally rs4988235, in the lactase gene (LCT) are associated with height, BMI, and LDL25,26,54. However, the association between rs4988235 and height has been suggested to be spurious due to uncorrected genome-wide ancestry27. Adjustment for genome-wide ancestry may not be sufficient to avoid false positive results and can mask true associations if ancestry is associated with the outcome55. Consistent with known potential confounding effects of ancestry3,56, we demonstrated that the lack of adjustment for both genome-wide and locus-specific ancestry can produce false positives in association studies using European-ancestry individuals. By adjusting our models for locus-specific ancestry in addition to genome-wide ancestry, associations of rs4988235 with height and LDL were eliminated. In contrast, the association between rs4988235 and BMI remained after correcting for both genome-wide and locus-specific ancestry, suggesting an effect on weight but not on height. These results suggest that residual confounding by subcontinental European ancestry can produce spurious associations in genetic association studies, with consequences for estimation of polygenic adaptation15 and polygenic risk scores16 and for fine-mapping of genetic associations. Importantly, our results warrant further analyses on the impact of unmodeled European admixture on GWAS, polygenic adaptation, and polygenic risk scores in European-ancestry individuals, including those in large biobanks such as the UK Biobank32 in Europe and the All of Us Research Program33 and the VA Million Veteran Program34 in the United States.
Fourth, for small studies, we tended to observe better model fit with adjustment for principal components derived from supervised analysis based on a common reference panel rather than for principal components derived from study-specific unsupervised analyses. However, the performance of unsupervised analysis approached or exceeded the performance of supervised analysis as the genetic diversity covered by the sample data approached or exceeded the genetic diversity covered by the external reference panel. European genetic diversity in our full panel covered by European American cohorts ranged from 9.7% to 55.7% whereas coverage reached 68.2% when all cohorts were combined. This result indicates that GWAS meta-analyses in which individual-level data cannot be or are not shared across studies should consider supervised analysis given a common reference. This recommendation does not depend on sample size, as even data sets on the scale of large biobanks do not necessarily cover a large proportion of ancestral diversity.
In conclusion, we demonstrated that European-ancestry individuals are admixed at the subcontinental level. Subcontinental admixture in Europeans and European Americans, if not properly accounted for, can produce false positive associations in genetic epidemiology studies due to incomplete correction for confounding by ancestry. Our study highlights the need for full control, at both genome-wide and locus-specific ancestry levels, for confounding in Europeans and European Americans. Potential consequences of residual confounding by subcontinental ancestry include the misestimation of polygenic adaptation and poor performance of genetic or polygenic risk scores.
Methods
Samples
We compiled genome-wide data from five different studies: the 1000 Genomes Project35, the Human Genome Diversity Project (HGDP)36, the Human Origins dataset37, a study of the Caucasus Mountains38, and a study of the Jewish Diaspora39 (Fig. 1A and Supplementary Data 1). Using these data, we created a data set that included 4796 individuals (worldwide reference panel), from which we extracted 1216 individuals from 79 European populations (European reference panel). We analyzed genome-wide array and phenotypic data from 17,684 European Americans from five genetic epidemiology cohorts, for which access was granted through dbGaP57: ARIC (phs000090.v1.p1), CARDIA (phs000285.v3.p2), FHS (phs000007.v32.p13), GENOA (phs000379.v1.p1), and MESA (phs000209.v13.p3).
|
|

