

Post by Admin on May 2, 2019 18:23:03 GMT
We observed that the AWKI-1 cluster also included five Aymara-speaking individuals from the Anapia Island and the  Rosa de Yanaque community of Lake Titicaca and three Quechua-speaking individuals from the Colca Canyon and Chuquibamba in Arequipa and Ayacucho, respectively. Thus, the AWKI-1 cluster mainly comprised individuals from the Lake Titicaca region and other southern locations, including Arequipa, located southwest of Cusco. On the contrary, the AWKI-2 cluster, which included K34, comprised seven individuals from Pacarictampu (K2, K24, K26, K27, K30, K31 and K49) and one from Puno.
Rosa de Yanaque community of Lake Titicaca and three Quechua-speaking individuals from the Colca Canyon and Chuquibamba in Arequipa and Ayacucho, respectively. Thus, the AWKI-1 cluster mainly comprised individuals from the Lake Titicaca region and other southern locations, including Arequipa, located southwest of Cusco. On the contrary, the AWKI-2 cluster, which included K34, comprised seven individuals from Pacarictampu (K2, K24, K26, K27, K30, K31 and K49) and one from Puno.
Coalescence time among haplotypes of AWKI-1 and AWKI-2 clusters
The evolutionary models of mean TMRCA over multiple generations using the Zhivotovsly mutation rates (Z-TMRCA) and using all available pedigree mutation rates (P-TMRCA) were calculated, and the most probable TMRCA for three closely related haplotypes (individuals K3, K9 and K36 in AWKI-1 cluster, and individuals K34, K19 and K24 in AWKI-2 cluster) was obtained. According to the P-TMRCA model, the common paternal ancestor for Sucso–Aucaylli families (included in the AWKI-1 cluster) was predicted to have occurred approximately 18 generations or 540 years ago (considering 30 years per generation). In the AWKI-2 cluster, which included one individual from ayllu Tumipampa (K34) and two individuals from San Sebastian (K19) and Pacarictampu (K24), the TMRCA was estimated to occur approximately 30 generations or 900 years ago (Supplemental Table 3c).
mtDNA results
Heterogeneity of maternal lineages among the Panakas
We identified four most common Native American mtDNA lineages as A2, B2, C1 and D1 and a rare maternal lineage D4h3 among others like M17a, a common lineage observed in Southeast Asia. The distribution of mtDNA lineages among the Panakas families and other individuals from San Sebastian–San Jerónimo and Pacarictampu (n = 51) showed a higher frequency of B2 (n = 29) such as that observed in many Andean populations (Sandoval et al. 2013b). Among other lineages, the distributions were C1 (n = 9), D1 (n = 6), A2 (n = 5), D4h3a (n = 1) and M17a (n = 1); their mtDNA SNPs relative to rCRS are listed in Supplemental Table 4.
First, the haplotypes of autochthonous mtDNA lineages (A2, B2, C1 and D1) of the Panakas were compared with South American Genographic Database (with 2335 selected individuals from different populations), including published data (Álvarez-Iglesias et al. 2007; Pauro et al. 2013; Fehren-Schmitz et al. 2015; Valverde et al. 2016; Llamas et al. 2016). To simplify the phylogenetic reconstruction, a group of closest haplotypes (n = 193) was selected (Fig. 3). In general, our analysis showed a close genetic relationship of the Panakas with native populations located south of Cusco in Peru and Bolivia.
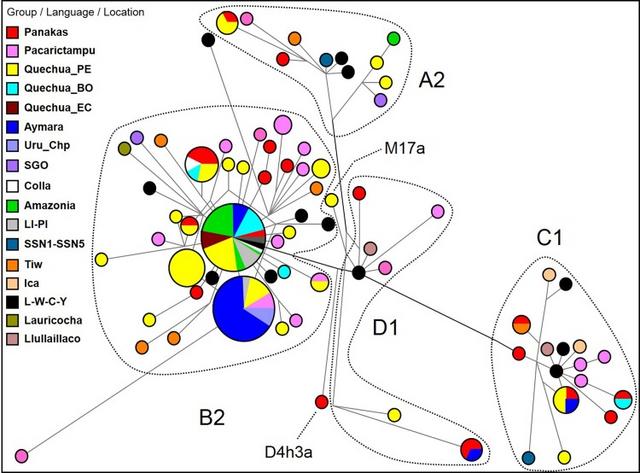
Fig. 3
Median-joining network for A2, B2, C1 and D1 control region mtDNA haplotypes among selected individuals (n = 193) from different populations. Different population groups (Group/Language/Location) are indicated using distinct colours. The mtDNA haplotypes are indicated with circles; the size of the circle is proportional to the number of individuals, and the branch length is proportional to the number of nucleotide changes. Population groups: the Panakas comprised individuals from all five ayllus of the San Sebastian and San Jerónimo districts; Peruvian Quechuas (Quechua_PE); Bolivian Quechuas (Quechua_BO); Ecuadorian Quechuas (Quechua_EC); Urus from Chipaya, Bolivia (Uru_Chp); Lima and Piura, Peru (LI-PI); SGO samples were from Santiago del Estero, Argentina (Pauro et al. 2013); Colla samples were from Jujuy, Argentina (Álvarez-Iglesias et al. 2007); SSN1–SSN5, Tiw (Tiwanaku), Ica, Llullaillaco and L–W–C–Y (Lima–Wari–Chancay–Ychsma) samples were from Llamas et al. (2016); and Lauricocha sample was from Huanuco (Fehren-Schmitz et al. 2015). Amazonia comprised samples from several Amazonian ethnic groups, including Andoas and Jivaro (Peru), Arawak, Tupi-Guarani, Cayubaba, Itonama and Movima (Bolivia) and Je and Puinavean (Brazil)
Among the B2 haplotypes, we observed two major groups of the closest haplotypes (73-263-499-16217 and 73-186-263-499-16217), which were shared by 70 individuals (including 4 from ancient DNA samples) and 23 individuals, respectively. The first group included individuals from different regions/languages of Peru, Bolivia, Ecuador and Brazil (Fig. 3). Additionally, three individuals from ayllus Sucso (K6 and K7) and Avayni (K41) were included in this group. The ancient DNA samples were from the pre-Inka cultures of Lima and Chancay (ACAD10789 and ACAD11200 samples, respectively; Llamas et al. 2016) and Ychsma (ACAD10713 and ACAD10720 samples; Valverde et al. 2016). The second group of shared haplotypes included mostly Aymara- and Quechua-speaking individuals from the Altiplano region as well as K25 and K26 from the Pacarictampu District. On the contrary, seven individuals shared the haplotype 73-204-207-263-499-16217, including three from ayllus Chima (K13 sample), Sucso (K33 sample) and Aucaylli (K36 sample), three Quechua-speaking individuals from Peru and Bolivia and a Colla individual from Jujuy/Salta provinces of Argentina (CO-07 sample; Álvarez-Iglesias et al. 2007).
In the A2 lineage, we observed a shared haplotype between K12 (from ayllu Sucso) and two individuals from the Colca Canyon (Arequipa). The C1 lineage included two shared haplotypes, one shared between K15 from Cusco, two individuals from Apurimac and one Aymara-speaking individual from Puno and another shared between K22 (from ayllu Aucaylli) and a Quechua-speaking individual from Bolivia. Surprisingly, a shared haplotype between K39 (from ayllu Sucso) and an ancient sample (ACAD13241) from Tiwanaku period dated 962 years ago (Llamas et al. 2016) was also identified. The D1 lineage included a shared haplotype between two samples from Cusco, K4 (from ayllu Sucso), K19 and an Aymara-speaking individual from Bolivia. On the contrary, an individual from Panakas (labelled as K11 sample from ayllu Sucso) belonged to the D4h3a lineage, which is found in different regions of South America (Catelli et al. 2011; Sevini et al. 2013; Gómez-Carballa et al. 2016) and shared a haplotype with a Quechua-speaking individual from Apurimac (sample Tor676, from Perego et al. 2009) (Supplemental Fig. 2).
 Rosa de Yanaque community of Lake Titicaca and three Quechua-speaking individuals from the Colca Canyon and Chuquibamba in Arequipa and Ayacucho, respectively. Thus, the AWKI-1 cluster mainly comprised individuals from the Lake Titicaca region and other southern locations, including Arequipa, located southwest of Cusco. On the contrary, the AWKI-2 cluster, which included K34, comprised seven individuals from Pacarictampu (K2, K24, K26, K27, K30, K31 and K49) and one from Puno.
Rosa de Yanaque community of Lake Titicaca and three Quechua-speaking individuals from the Colca Canyon and Chuquibamba in Arequipa and Ayacucho, respectively. Thus, the AWKI-1 cluster mainly comprised individuals from the Lake Titicaca region and other southern locations, including Arequipa, located southwest of Cusco. On the contrary, the AWKI-2 cluster, which included K34, comprised seven individuals from Pacarictampu (K2, K24, K26, K27, K30, K31 and K49) and one from Puno.Coalescence time among haplotypes of AWKI-1 and AWKI-2 clusters
The evolutionary models of mean TMRCA over multiple generations using the Zhivotovsly mutation rates (Z-TMRCA) and using all available pedigree mutation rates (P-TMRCA) were calculated, and the most probable TMRCA for three closely related haplotypes (individuals K3, K9 and K36 in AWKI-1 cluster, and individuals K34, K19 and K24 in AWKI-2 cluster) was obtained. According to the P-TMRCA model, the common paternal ancestor for Sucso–Aucaylli families (included in the AWKI-1 cluster) was predicted to have occurred approximately 18 generations or 540 years ago (considering 30 years per generation). In the AWKI-2 cluster, which included one individual from ayllu Tumipampa (K34) and two individuals from San Sebastian (K19) and Pacarictampu (K24), the TMRCA was estimated to occur approximately 30 generations or 900 years ago (Supplemental Table 3c).
mtDNA results
Heterogeneity of maternal lineages among the Panakas
We identified four most common Native American mtDNA lineages as A2, B2, C1 and D1 and a rare maternal lineage D4h3 among others like M17a, a common lineage observed in Southeast Asia. The distribution of mtDNA lineages among the Panakas families and other individuals from San Sebastian–San Jerónimo and Pacarictampu (n = 51) showed a higher frequency of B2 (n = 29) such as that observed in many Andean populations (Sandoval et al. 2013b). Among other lineages, the distributions were C1 (n = 9), D1 (n = 6), A2 (n = 5), D4h3a (n = 1) and M17a (n = 1); their mtDNA SNPs relative to rCRS are listed in Supplemental Table 4.
First, the haplotypes of autochthonous mtDNA lineages (A2, B2, C1 and D1) of the Panakas were compared with South American Genographic Database (with 2335 selected individuals from different populations), including published data (Álvarez-Iglesias et al. 2007; Pauro et al. 2013; Fehren-Schmitz et al. 2015; Valverde et al. 2016; Llamas et al. 2016). To simplify the phylogenetic reconstruction, a group of closest haplotypes (n = 193) was selected (Fig. 3). In general, our analysis showed a close genetic relationship of the Panakas with native populations located south of Cusco in Peru and Bolivia.
Fig. 3
Median-joining network for A2, B2, C1 and D1 control region mtDNA haplotypes among selected individuals (n = 193) from different populations. Different population groups (Group/Language/Location) are indicated using distinct colours. The mtDNA haplotypes are indicated with circles; the size of the circle is proportional to the number of individuals, and the branch length is proportional to the number of nucleotide changes. Population groups: the Panakas comprised individuals from all five ayllus of the San Sebastian and San Jerónimo districts; Peruvian Quechuas (Quechua_PE); Bolivian Quechuas (Quechua_BO); Ecuadorian Quechuas (Quechua_EC); Urus from Chipaya, Bolivia (Uru_Chp); Lima and Piura, Peru (LI-PI); SGO samples were from Santiago del Estero, Argentina (Pauro et al. 2013); Colla samples were from Jujuy, Argentina (Álvarez-Iglesias et al. 2007); SSN1–SSN5, Tiw (Tiwanaku), Ica, Llullaillaco and L–W–C–Y (Lima–Wari–Chancay–Ychsma) samples were from Llamas et al. (2016); and Lauricocha sample was from Huanuco (Fehren-Schmitz et al. 2015). Amazonia comprised samples from several Amazonian ethnic groups, including Andoas and Jivaro (Peru), Arawak, Tupi-Guarani, Cayubaba, Itonama and Movima (Bolivia) and Je and Puinavean (Brazil)
Among the B2 haplotypes, we observed two major groups of the closest haplotypes (73-263-499-16217 and 73-186-263-499-16217), which were shared by 70 individuals (including 4 from ancient DNA samples) and 23 individuals, respectively. The first group included individuals from different regions/languages of Peru, Bolivia, Ecuador and Brazil (Fig. 3). Additionally, three individuals from ayllus Sucso (K6 and K7) and Avayni (K41) were included in this group. The ancient DNA samples were from the pre-Inka cultures of Lima and Chancay (ACAD10789 and ACAD11200 samples, respectively; Llamas et al. 2016) and Ychsma (ACAD10713 and ACAD10720 samples; Valverde et al. 2016). The second group of shared haplotypes included mostly Aymara- and Quechua-speaking individuals from the Altiplano region as well as K25 and K26 from the Pacarictampu District. On the contrary, seven individuals shared the haplotype 73-204-207-263-499-16217, including three from ayllus Chima (K13 sample), Sucso (K33 sample) and Aucaylli (K36 sample), three Quechua-speaking individuals from Peru and Bolivia and a Colla individual from Jujuy/Salta provinces of Argentina (CO-07 sample; Álvarez-Iglesias et al. 2007).
In the A2 lineage, we observed a shared haplotype between K12 (from ayllu Sucso) and two individuals from the Colca Canyon (Arequipa). The C1 lineage included two shared haplotypes, one shared between K15 from Cusco, two individuals from Apurimac and one Aymara-speaking individual from Puno and another shared between K22 (from ayllu Aucaylli) and a Quechua-speaking individual from Bolivia. Surprisingly, a shared haplotype between K39 (from ayllu Sucso) and an ancient sample (ACAD13241) from Tiwanaku period dated 962 years ago (Llamas et al. 2016) was also identified. The D1 lineage included a shared haplotype between two samples from Cusco, K4 (from ayllu Sucso), K19 and an Aymara-speaking individual from Bolivia. On the contrary, an individual from Panakas (labelled as K11 sample from ayllu Sucso) belonged to the D4h3a lineage, which is found in different regions of South America (Catelli et al. 2011; Sevini et al. 2013; Gómez-Carballa et al. 2016) and shared a haplotype with a Quechua-speaking individual from Apurimac (sample Tor676, from Perego et al. 2009) (Supplemental Fig. 2).

