|
|
Post by Admin on Nov 3, 2021 4:33:48 GMT
3. Linguistic background of the population history in Xinjiang Although many different languages through the ages have been spoken in the region, only one group is considered autochthonous, the Tocharian languages composed of Tocharian A and B. These languages are attested along the northern rim of the Tarim Basin during the middle of the first millennium CE. Using comparative methods, the common ancestor of these two languages, Proto-Tocharian, is estimated to have diverged at around 500 BC, presumably also in the northern Tarim Basin. By comparing its central vocabulary (e.g., numerals, pronouns, and central grammar), Proto-Tocharian reveals itself to be related to all other Indo-European branches (incl. Greek, Latin, Germanic, Slavic, and Indo-Iranian) through their ancestral language Proto-Indo-European, which was spoken no later than 3000 BCE in the Pontic-Caspian Steppe. This suggests that Tocharian language branch experienced a significant eastward migration of its speakers during prehistory20. Parts of this prehistory may be gleaned from contacts with other languages. For example, a number of rather distinctive features of the Tocharian branch (including both sound and grammatical system) suggest extensive and intimate contacts with a Uralic language (likely related or similar to Finnish, Hungarian, Samoyedic, and several other minor languages in Russia21,22), while, on the other hand, certain Uralic lexical items (denoting, for example, numerals and metallurgy) appear to be of Tocharian provenance23. There are mutual borrowings between Proto-Tocharian and early Turkic (the predecessor of all modern Turkic languages, including Turkish, Chuvash, and Uighur), while Chinese elements within Tocharian24 appear to postdate Tocharian borrowings into Chinese25. A small number of words has tentatively been associated with an extinct substrate language, possibly affiliated with the BMAC culture of Central Asia26. Indo-Iranian, the other Indo-European branch to migrate into Central Asia, similarly wielded influence on the Tocharian languages. Namely, their mainly lexical contributions are as complex as they are sustained, beginning with an unattested Old Iranian dialect already present in the Steppe Zone before Tocharian entered the Tarim Basin and continuing through the successive political, mercantile, and religious regimes of the Bactrians, Sogdians, Khotanese, and the Indic Prakrits that successively entered the region from the west27. 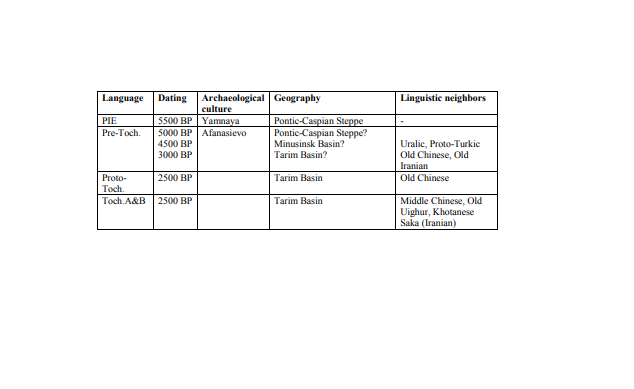 |
|
|
|
Post by Admin on Nov 3, 2021 20:09:24 GMT
4. Detailed description of genetic isolation of the Tarim group The Tarim_EMBA1 and Tarim_EMBA2 groups, although geographically separated by over 600 km of desert, cluster closely in PC space (Figs. 1-2) and show greatly reduced interindividual genetic differences, as measured by extremely high outgroup-f3 values and low pairwise mismatch rate (“pmr”) values of pseudo-diploid genotypes. The reduced genetic difference among the Tarim individuals is comparable to the level of 1st degree relatives in other published Bronze Age populations from the Eurasian steppe28 (Extended Data Fig. 4A, C). However, a lack of long runs of homozygosity (ROH) segments expected for such close relatives suggests that a population bottleneck and not close kinship nor recent inbreeding is the likely explanation for the reduced genetic diversity (Extended Data Fig. 4B). Such
observations were further supported by the fact that 12 out of 13 Tarim Basin individuals
belong to a single mitochondrial haplogroup, C4 (Extended Data Table 1). Likewise,
although limited in number, the two Xiaohe males belong to the Y-chromosome haplogroup
R1b1c, which falls outside of the R1b1a clade representative of the Yamnaya and Afanasievo
individuals (Extended Data Table 1; Extended Fig. 4D; Supplementary Data S1B). The Ychromosome of the Beifang male belongs to a basal R1 or R1b haplogroup but shares no derived allele with R1a or sublineage of R1b, similar to that of MA-1 (R*, xR1, xR2)29
(Extended Data Table 1; Extended Fig. 4D).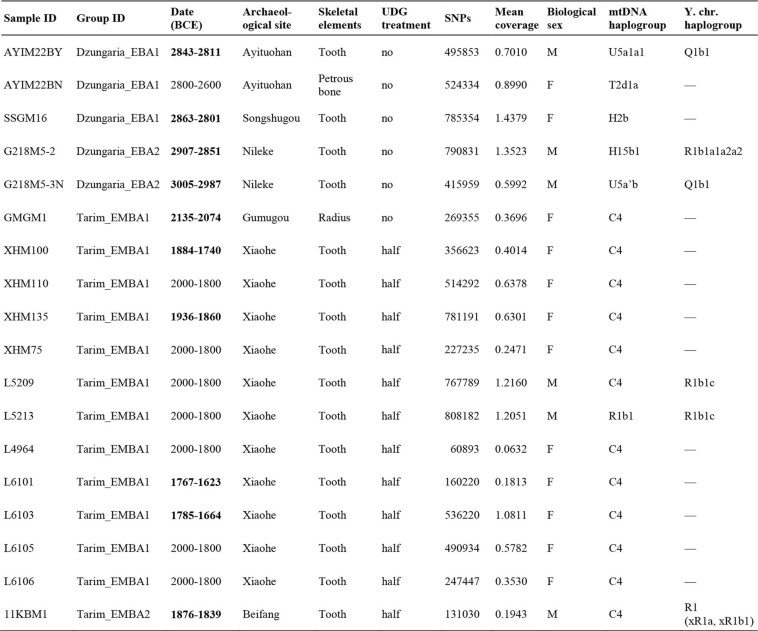 5. Tarim mummies and the pre-pastoralist Central Asian genetic substratum The Tarim mummies are among only a few known Holocene populations that derive the majority of their ancestry from Pleistocene ANE groups, who once made up the huntergatherer populations of southern Siberia, and which are represented by individual genomes from the archaeological sites of Mal’ta (MA-1)29 and Afontova Gora (AG3)30. Interestingly, we observe that most Bronze Age and pre-Bronze Age populations with substantial ANE ancestry, such as Botai_CA from Eneolithic northern Kazakhstan, Kumsay_EBA and Mereke_MBA from western Kazakhstan, West_Siberia_N from Neolithic southern Russia, Okunevo_EMBA from the Minusinsk Basin, Chemurchek from EMBA Altai mountains, and Aigyrzhal_BA, Dali_EBA, Kanai_MBA from the IAMC region, show the highest outgroupf3 value with Tarim_EMBA1, suggesting that the Tarim mummies are currently the best representative of the pre-pastoralist ANE-related population that once inhabited Central Asia and southern Siberia (Extended Data Fig. 2A), even though Tarim_EMBA1 postdates these populations in time. This calls for a revision of previous admixture models of these populations, which were based on Botai_CA or West_Siberia_N31,32,33, to include Tarim_EMBA1 as their ANE source (Supplementary Data S1F-H,I). Applying qpAdm, we successfully modeled the high-ANE group West_Siberia_N as a mixture of Tarim_EMBA1 (67%) and Eastern European Hunter-Gatherers (EHG) (Supplementary Data S1I). Botai _CA shows a similar profile but requires an additional Eastern Eurasian contribution (5-12%) (Supplementary Data S1I; Extended Data Table 3). Chemurchek, Aigyrzhal_BA, and Dali_EBA fit to the three-way mixture of Tarim_EMBA1 (14-54%), Dzungaria_EBA1 (30-67%) and Geoksyur_EN (9-48%; a pre-BMAC proxy) while Chemurchek and Aigyrzhal_BA do not fit to Tarim_EMBA1+Afanasievo+Geoksyur_EN (Supplementary Data S1F-G). Mereke_MBA from western Kazakhstan also fit to Tarim_EMBA1+Dzungaria_EBA1 but not to Tarim_EMBA1+Afanasievo (Supplementary Data S1G). In contrast, Kumsay_EBA from western Kazakhstan fit to Tarim_EMBA1+Afanasievo+Geoksyur_EN but not to Tarim_EMBA1+Dzungaria_EBA1+Geoksyur_EN (Supplementary Data S1G; Extended Data Table 3). These results confirm that the genetic profile represented by the Tarim mummies is a good proxy for the ANE substratum that was once more widely distributed across pre-pastoralist Central Asia (Fig. 3C), and suggests that Dzungaria_EBA locally relayed Afanasievo ancestry into northern Xinjiang and its neighboring regions, and that IAMC/BMAC-related ancestry spread into Xinjiang independent of the dispersal of the Afanasievo herders. We find that the Chemurchek, an EBA pastoralist culture that succeeds the Afanasievo in both the Dzungarian Basin and Altai mountains, derive from these three ancestry streams, which helps to explain both the IAMC/BMAC-related ancestry previously noted in Chemurchek individuals31 as well as their reported cultural and genetic affiliations to Afanasievo groups33. Importantly, however, none of these admixed groups were the source population for the Tarim Basin Xiaohe culture, who we instead find were a highly isolated local autochthonous population. The extreme genetic bottleneck specific to Tarim_EMBA may have been related to the EMBA colonization of this challenging desert environment. |
|
|
|
Post by Admin on Nov 8, 2021 22:42:16 GMT
Evidence that a West-East admixed population lived in the Tarim Basin as early as the early Bronze Age Abstract Background The Tarim Basin, located on the ancient Silk Road, played a very important role in the history of human migration and cultural communications between the West and the East. However, both the exact period at which the relevant events occurred and the origins of the people in the area remain very obscure. In this paper, we present data from the analyses of both Y chromosomal and mitochondrial DNA (mtDNA) derived from human remains excavated from the Xiaohe cemetery, the oldest archeological site with human remains discovered in the Tarim Basin thus far. Results Mitochondrial DNA analysis showed that the Xiaohe people carried both the East Eurasian haplogroup (C) and the West Eurasian haplogroups (H and K), whereas Y chromosomal DNA analysis revealed only the West Eurasian haplogroup R1a1a in the male individuals. Conclusion Our results demonstrated that the Xiaohe people were an admixture from populations originating from both the West and the East, implying that the Tarim Basin had been occupied by an admixed population since the early Bronze Age. To our knowledge, this is the earliest genetic evidence of an admixed population settled in the Tarim Basin. Background The Tarim Basin in western China, positioned at a critical site on the ancient Silk Road, has played a significant role in the history of human migration, cultural developments and communications between the East and the West. It became famous due to the discovery of many well-preserved mummies within the area. These mummies, especially the prehistoric Bronze Age 'Caucasoid' mummies, such as the 'Beauty of Loulan', have attracted extensive interest among scientists regarding who were these people and where did they come from. Based on analyses of human remains and other archaeological materials from the ancient cemeteries (dated from approximately the Bronze Age to the Iron Age), there is now widespread acceptance that the first residents of the Tarim Basin came from the West. This was followed, in stages, by the arrival of Eastern people following the Han Dynasty [1, 2]. However, the exact time when the admixture of the East and the West occurred in this area is still obscure [3]. In 2000, the Xinjiang Archaeological Institute rediscovered a very important Bronze Age site, the Xiaohe cemetery, by utilizing a device employing the global positioning system. The rediscovery of this cemetery provided an invaluable opportunity to further investigate the migrations of ancient populations in the region. The Xiaohe cemetery (40°20'11"N, 88°40'20.3"E) is located in the Taklamakan Desert of northwest China, about 60 km south of the Peacock River and 175 km west of the ancient city of Kroraina (now Loulan; Figure 1). It was first explored in 1934 by Folke Bergman, a Swedish archaeologist, but the cemetery was lost sight of until the Xinjiang Archaeological Institute rediscovered it in 2000. The burial site comprises a total of 167 graves. Many enigmatic features of these graves, such as the pervasive use of sexual symbolism represented by tremendous numbers of huge phallus-posts and vulvae-posts, exaggerated wooden sculptures of human figures and masks, well-preserved boat coffins and mummies, a large number of textiles, ornaments and other artifacts, show that the civilization revealed at Xiaohe is different from any other archaeological site of the same period anywhere in the world [3]. Figure 1 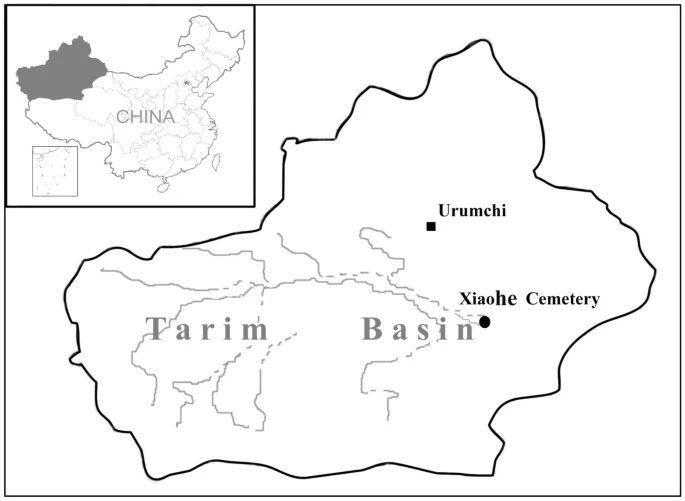 The geographical position of Xiaohe cemetery. The larger map shows Xinjiang, shown also in the shaded section of the map of China. The entire necropolis can be divided, based on the archeological materials, into earlier and later layers. Radiocarbon measurement (14C) dates the lowest layer of occupation to around 3980 ± 40 BP (personal communications; calibrated and measured by Wu Xiaohong, Head of the Laboratory of Accelerator Mass Spectrometry, Peking University), which is older than that of the Gumugou cemetery (dated to 3800). To date, these are the oldest human remains that have been excavated in the Tarim Basin [3]. A genetic study of these invaluable archeological materials will undoubtedly provide significant insights into the origins of the people of the Tarim Basin. We examined the DNA profiles on both the maternal and the paternal aspects for all the morphologically well-preserved human remains from the lowest layer of the Xiaohe cemetery. We used these data to determine the population origins, to provide insights into the early human migration events in the Tarim Basin and, finally, to offer an expanded understanding of the human history of Eurasia. |
|
|
|
Post by Admin on Nov 9, 2021 2:58:25 GMT
Methods
Sampling
The excavation of the Xiaohe cemetery began in 2002. The lowest layer of the cemetery, comprising a total of 41 graves of which 37 have human skeletal remains, was excavated by the Xinjiang Archaeological Institute and the Research Center for Chinese Frontier Archaeology of Jilin University from 2004 to 2005. After the appropriate recording, the skeletal remains of 30 well-preserved individuals, together with sandy soil, were packed in cardboard boxes and sent to the ancient DNA laboratory of Jilin University, where they were stored in a dry and cool environment. All the samples were collected by two highly skilled scientists in our group, equipped with gloves and facemasks. As a result of the saline and alkaline character of the sand, the dry air and good drainage, the human remains are in excellent conditions. One intact femur and two tooth samples for each set of human remains were selected for DNA analysis, except for samples 84 and 121, which have only tooth samples. The archaeological information regarding the samples used in this study is summarized in Additional File 1.
Contamination precautions and decontamination
Previous studies have shown that the recovery of authentic ancient human DNA is possible [4, 5] when strict precautions are taken to prevent contamination. The following is a summary of the measures taken to avoid contamination and to ensure authenticity in the present study.
(1) Bone powdering, DNA extraction and amplification were carried out in three separate rooms in our laboratory which is dedicated solely to ancient DNA studies; all staff wore laboratory coats, facemasks and gloves and strict cleaning procedures [frequent treatment with bleach and ultraviolet (UV) light] were applied.
(2) In order to prevent contamination, polymerase chain reaction (PCR) tubes, tips, microcentrifuge tubes and drills were sterilized by autoclaving. Some of the reagents were exposed to UV light at 254 nm for at least 30 min. Tip boxes were soaked in 10% sodium hypochlorite solution. Extraction and amplification blanks were included in every PCR assay in order to detect any potential contamination from sample processing or reagents even though they were guaranteed DNA-free by the manufacturers.
(3) Multiple extractions and amplifications from the same individual were undertaken at different times and from two different parts of the skeleton by three different laboratory members.
(4) Three samples were sent to Fudan University in Shanghai, China, for an independent repetition.
(5) Cloning analysis was performed with all the samples, in order to detect potential heterogeneity in the amplification products due to contamination, DNA damage or jumping PCR.
(6) Different length fragments were amplified. Since there is an inverse correlation between fragment length and amplification efficiency for ancient DNA, contamination from modern DNA could be identified by this assay.
(7) Ancient DNA from animal remains (goat or cattle) found at the same site was isolated and amplified using the same procedures as those used for the human ancient DNA, again providing a negative control for our study.
(8) The sex of some of the morphologically intact individuals was determined by amplifying the amelogenin (AMG) gene and the results were compared to that of the morphological examination in order to monitor any potential contamination in the extraction.
(9) DNA samples from all laboratory excavators and staff members involved in the project were genetically typed and recorded for comparison with the haplotypes of all ancient samples. This is critical in order to ensure the accuracy of the generated ancient DNA results [6–9]. The information for people involved in this project is listed in Table 1.
Table 1 Mitochondrial DNA haplotypes of all persons involved in processing Xiaohe samples.
Investigators Sex HVRI polymorphism site Appendix
Excavators
1 Male 16189 16223 16278
2 Male 16093 16124 16223 16311 16316
3 Male 16223 16294 16362
4 Male 16223 16260 16298 *
5 Male 16092 16111 16261
6 Male 16300 16362
7 Female 16111 16129 16266 16304 *
8 Male 16221
9 Male 16126 16294 16296 16304
10 Male 16085 16209 16311
11 Male 16356
12 Male 16136 16356
Laboratory researchers
1 Female 16136 16183 16189 16217 16218 16239 16248 *
2 Female 16223 16245 16362 16367
3 Male 16183 16189 16223 16234 16290 16362
4 Female 16126 16174 16223 16311 16362 *
5 Male 16112 16223 16362
6 Male 16213 16223 16298 16327
7 Male 16189 16304
In the laboratory, the numbers 1, 2, 3 and 4 represent the staff participating in this study, 5, 6 and 7 represent the staff working in the laboratory but not directly concerned with this study. The *represents the primary researchers
|
|
|
|
Post by Admin on Nov 9, 2021 20:46:30 GMT
Sample preparation and DNA extraction
The bone and tooth samples were processed independently. A fragment of bone, about 3 cm long, was cut from the intact femur or tibia by sawing. In order to remove any possible surface contamination of the samples by external DNA, each bone was drilled three times with three different drills to remove a layer about 1-3 mm from the top after removing the external soil using brush, and then soaked in a 5% sodium hypochlorite solution for 10 min, rinsed with distilled water and absolute alcohol successively and UV-irradiated (254 nm) on all sides for at least 45 min in a clean room. The samples were then pulverized by Freezer Mill 6850 after immersion in liquid nitrogen. Intact teeth were handled differently: they were soaked in a 5% sodium hypochlorite solution for 15 min after a preliminary treatment in which they were wiped with 10% sodium hypochlorite and then rinsed with absolute alcohol. After that, all sides of the samples were exposed to UV radiation (254 nm) for a minimum of 20 min before the sample was ground to powder by Freezer Mill 6750. DNA was extracted by means of a silica-based protocol [10]. One extraction blank was included for every three ancient samples. In brief, 0.5-2 g tooth/bone powder was incubated about 20 h at 50°C in lysis solution (1 mL 10% SDS, 4 ml EDTA (pH 8; 0.5 M, Promega, WI, USA), 100 uL of 10 mg/ml proteinase K (Merck, Darmstadt, Germany). After centrifugation, the solution was subsequently concentrated with centricons (Millipore, MA, USA) up to about 100 μL volume, and then the extraction proceeded according to the handbook of the QIAquick DNA Purification Kit (Qiagen, Hilden, Germany).
DNA amplification, cloning, and sequencing
The nucleotide positions 16035-16409 of the mitochondrial genome was amplified by two overlapping primer pairs. In addition, a number of coding-region mtDNA polymorphisms were typed, which are diagnostic for major branches in the mtDNA tree: Haplogroups R(12705C), UK(12308G), HV(14766T), H(7028C), R1(4917G), R11(10031C) and C4(11969A) were identified by direct sequencing and haplogroups M(10400T), F(3970T) and C(14318C) were examined by using amplified product-length polymorphisms method [11–13]. The B haplogroup was identified based on 9-bp deletion in np8280. Some Y-chromosomal single nucleotide polymorphisms (Y-SNPs) were typed, which are diagnostic for major branches in the Y chromosome haplogroup tree [14, 15]: Haplogroups F(M89T), K(M9G), P(M45A), R1(M173A), and R1a1a(M198A) were identified by direct sequencing. The primers used in HVRI and diagnostic SNP markers are shown in Table 2.
Table 2 The primers used in this study.
Haplogroup/AMG Primer SNP Length
HVRI-AB L16017 5'-TTCTCTGTTCTTTCATGGGGA
H16251 5'-GGAGTTGCAGTTGATGTGTGA Sequencing 235 bp
HVRI-CD L16201 5'-CAAGCAAGTACAGCAATCAAC
H16409 5'-AGGATGGTGGTCAAGGGA Sequencing 209 bp
M 10400T 5'-taattaTACAAAAAGGATTAGACTGtgCT
10400C 5'-TACAAAAAGGATTAGACaGAACC
10400R 5'-GAAGTGAGATGGTAAATGCTAG 10400T 149 bp/142 bp
R L12604 5'-ATCCCTGTAGCATTGTTCG
H12754 5'-GTTGGAATAGGTTGTTAGCG 12705C 151 bp
UK L12247 5'-TAACAACATGGCTTTCTCAACT
H12377 5'-GAAGTCAGGGTTAGGGTGGT 12308G 132 bp
C L14318T 5'-CCTTCATAAATTATTCAGCTTCCaACACTAT
L14318C 5'-aaaaagctaCATAAATTATTCAGCTTCCTACtCTAC
H14318R 5'-TTAGTGGGGTTAGCGATGGA 14318C 110 bp/115 bp
C4 L11845 5'- AAGCCTCGCTAACCTCGCC
H12120 5'- GGGTGAGTGAGCCCCATTG 11969A 176 bp
B L8215 5' ACAGTTTCATGCCCATCGTC '
H8297 5' ATGCTAAGTTAGCTTTACAG CoII/tRNAlys
9-bp deletion 121 bp/112 bp
R1 L4812 5'- GTCCCAGAGGTTACCCAAG
H4975 5'- CCACCTCAACTGCCTGCTA 4917G 164 bp
R11 L9920 5'- CGCCTGATACTGGCATTTTGT
H101075' -GTAGTAAGGCTAGGAGGGTGTTG 10031C 188 bp
HV L14668 5'- CATCATTATTCTCGCACGG
H14831 5'- CGGAGATGTTGGATGGGGT 14766T 164 bp
F 3970T 5' taaaaTGTATTCGGCTATGAAGAtTAA
3970C 5' GTGTATTCGGCTATGAAGtATAG
3970R 5' AGTCTCAGGCTTCAACATCG 3970T 70 bp/66 bp
H L6966 5'-GGCATTGTATTAGCAAACTCAT
H7118 5'-TAGGGTGTAGCCTGAGAATAG 7028C 152 bp
AMG AMG1 5'-CCTGGGCTCTGTAAAGAATAG
AMG2 5'-CAGAGCTTAAACTGGGAAGCTG 115 bp/121 bp
Paternal hg F Forward 5' CCACAGAAGGATGCTGCTCA
Reverse r 5' CACACTTTGGGTCCAGGATCAC M89T 125 bp
Paternal hg K Forward 5' GGACCCTGAAATACAGAAC
Reverse 5' AAGCGCTACCTTACTTACAT M9G 128 bp
Paternal hg P Forward 5' GGGTGTGGACTTTACGAAC
Reverse 5' AAATCCTACTATCTCCTGGC M45A 129 bp
Paternal hg R1 Forward 5' TTACTGTAACTTCCTAGAAAATTGG
Reverse 5' ATCCTGAAAACAAAACACTGG M173C 126 bp
Paternal hg R1a1a Forward 5' CTCTTTAAGCCATTCCAGTCA
Reverse 5' AAACATTACATGAGAAATTGCTG M198A 113 bp
PCR amplifications were performed in 20 μL reactions with 3 μl of extract, 1 U Taq DNA polymerase (Fermentas, Ontario, Canada), and 1.5×buffer (Fermentas), 1.5 mg/ml BSA, 2.5 mM MgCl2, 0.2 mM dNTP (Promega, USA), and 400 pmol for each primer (Sangong, China). The cycle conditions used a Mastercycler gradient (Eppendorf, Germany) consisting of 40 cycles at 94°C for 1 min, 59°C -52°C for 1 min, and 72°C for 1 min, with a first denatured step of 94°C for 5 min and a last extended step of 72°C for 10 min. PCR products were purified with QIAamp quick DNA Purification Kit (Qiagen) and sequenced with BigDye 3.1 in an ABI 310 DNA sequencer (Applied Biosystems, CA, USA). The PCR products were cloned with pGEM-T (Promega), following the supplier's instructions. Extraction, amplification, cloning, and sequencing were undertaken in slightly varying conditions for different samples (Table 3).
Table 3 Analysis strategy of the samples.
Sample MtDNA-HVRI MtDNA Y chromosome Sexing Independent
No. haplotype haplogroup haplogroup Morphological Molecular repetition
100 298-327 C4 Female Female √
102 298-327 C4 Female -
106 298-327 C4 R1a1a Male Male
107 223-298-309-327 C4 Female -
109 298-327 C4 Female -
110 298-327 C4 Female -
111 223-298-309-327 C4 R1a1a Male Male
115 298-327 C4 R1a1a Male Male
117 223-304 M* Female Female
119 93-134-224-311-390 K Female Female √
120 189-192-311 R* R1a1a Male Male
121 183-189-192-311 R* R1a1a Male Male
127 223-298-309-327 C4 Female Female √
128 260 H Female Female
131 189-192-311-390 R* Female Female
132 298-327 C4 Female Female
135 223-298-309-327 C4 Female Female
136 298-327 C4 R1a1a Male Male
138 298-327 C4 - Female -
139 298-327 C4 R1a1a Male Male
Note: √ means we performed this kind of strategy to the sample; - indicates that the targeted DNA fragment could not be amplified for a given sample.
Data analysis
Sequence alignments were performed using the Clustalx1.8 software. Comparison of DNA sequence homology was performed with Blast from the National Centre for Biotechnology Information. Median networks were constructed by Network 4.5 using a reduction threshold and the different weights for SNPs loci but the same weight for all HVSI polymorphism loci. No statistical analysis was performed in this study due to the small sample size.
|
|

