|
|
Post by Admin on May 31, 2019 18:30:07 GMT
Comparing marker systems: Massively different ancestry on the male and female lines of descent The mtDNA patterns suggest much higher levels of autochthonous variation on the maternal line (~70–90%) compared to the overall GW estimate (about a half to two-thirds), the implications of which we further explored by studying Y-chromosome lineages. We used the five South Asian 1KGP populations, which comprise unbiased population data, and are the only available datasets that can be simultaneously analysed for GW, mtDNA and Y-chromosome variation. A markedly higher proportion of male lineages of likely West Eurasian origin, of ~50–90%, is evident across the Subcontinent (Fig. 3c), in comparison with both the maternal line (Fig. 3b) and the GW pattern (Fig. 3d). A sex-biased pattern is also seen in the East Asian fraction, but is much less marked, with a much lower contribution overall and mainly focused on speakers of Tibeto-Burman and Austroasiatic language families [22]. 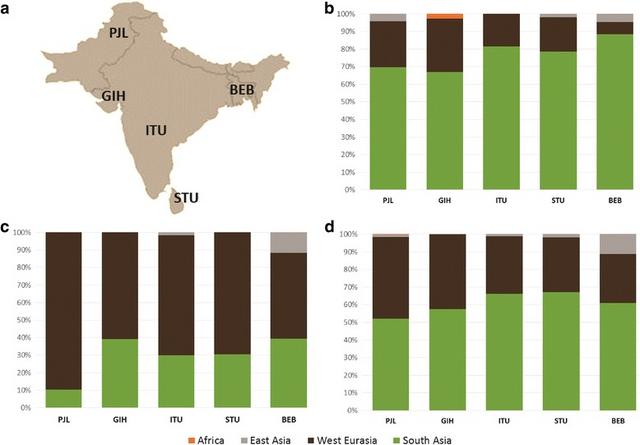 Fig. 3 The ancestry of South Asian 1KGP populations according to different molecular markers: a sampling locations, b mtDNA lineages, c Y-chromosome lineages and d GW components (based on ADMIXTURE, K = 7). Putative origin of the uniparental lineages present in the populations in the Additional file 1; Table S4. Population codes: PJL—Punjabi from Lahore, Pakistan; GIH—Gujarati Indian from Houston, Texas; ITU—Indian Telugu from the UK; STU—Sri Lankan Tamil from the UK; BEB—Bengali from Bangladesh Discussion Towards a more fine-grained history of South Asian settlement The phylogeographic analysis of non-recombining marker systems offers certain strengths that can complement genome-wide analyses. In particular, the polarity of gene trees allows us to identify the source of dispersals, and the increasing precision of molecular clocks for mtDNA and the Y chromosome allows us to date events during the ancestry of lineages with some confidence. However, the contribution of the two systems to the overall picture is not always the same, and South Asia is a case in point. Here it is clear from our analyses that there is a very strong sex bias in the ancestry of South Asians. The female line of descent is mostly autochthonous and traces back to the first settlement ~55 ka. However, the male line of descent emphasizes more recent ancestry, since the LGM, from Southwest Asia and Central Asia. The mtDNA is, therefore, at present a uniquely powerful tool for teasing out multiple settlement episodes and dating them, establishing a timeline for demographic events in South Asia. By combining that information with GW patterns and Y-chromosome data, and taking into account also archaeological, palaeontological and palaeoclimatological data, we can reconstruct an outline demographic history of human populations in South Asia that captures some of the complexity of the region and moves beyond simplistic models of admixture between autochthonous Indians and invading Neolithic farmers or Indo-Aryan speakers (Fig. 4). 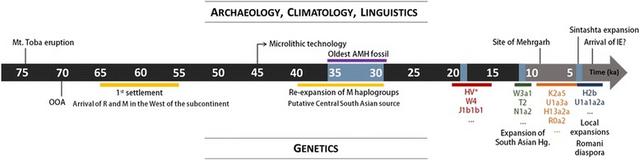 Fig. 4 Timeline for AMH evolution in South Asia based on genetic, archaeological, climatological and linguistic evidence. Black and grey portions of the arrow represent Pleistocene and Holocene, respectively. Blue sections correspond to periods of climate changes: dryer periods between 35 and 30 ka, Last Glacial Maximum ~18 ka, Younger Dryas ~12 ka and the “4.2 ka” event. Lineages in red stand for the putative Late Glacial/postglacial genetic influx from West Eurasia; green for migrations from West Eurasia around the Pleistocene/Holocene transition, orange for the Neolithic period and blue for the genetic events in the last 4 ka Resolving the Pleistocene modern human settlement Evidence is mounting that haplogroups M, N and R had a common origin and entered South Asia together, following a southern coastal route from Eastern Africa after the Toba eruption [2, 3]. This is supported by their global (non-African) distribution [3], including the detection of basal M lineages, M0 and M1, in Europe and the Near East respectively [65, 80, 81], and their similarity in age elsewhere either using both a stipulated clock [30] and aDNA-driven estimation [65]. We have resolved the issue of the anomalously low age of haplogroup M in South Asia by showing that the discrepancy vanishes when we take into account the regional origin of each basal branch. In the west, M dates to 55.3 [45.1; 65.9] ka, overlapping with the founder age of R (Fig. 4). The anomaly is most likely a result of major expansions across the Subcontinent ~45–35 ka: there is an increment in N e in M across the Subcontinent ~40 ka, coinciding with the appearance and spread of microlithic technology and greater aridity [67, 68]. The lower age of M is most striking in central India, which is also the centre of gravity of the dramatic radiation of M4’67, which dates to ~40 ka. Microlithic technology can be traced to ~45 ka in central India [82], supporting this region as the likely source of the re-expansion. Re-peopling after the Last Glacial Maximum Although South Asia displays a very high level of indigenous variation, the region subsequently received substantial genetic input from both west and east, dramatically re-shaping its genetic structure. Broadly, South Asian populations are closer to the Caucasus and Central Asian groups rather than to other West Eurasian populations. Pakistanis and Gujaratis in particular carry a preponderance of the “Ancestral North Indian” (ANI) gene pool, contrasting with the ASI or autochthonous population of the Subcontinent [25, 26]. However, our results suggest that this profile is due to multiple dispersals from the north-west, from several distinct sources, rather than just one or two major admixture events in the Neolithic/Bronze Age. In fact, we see mtDNA lineages from Southwest Asia start to arrive as early as ~20 ka. This was a time of short-lived relative global warmth following the peak of the last glaciation, which might have triggered population movements in several regions [83]. Some lineages arrived in Late Glacial times, again from a Southwest Asian refugium, mirroring the situation in Europe [84]. After ~12 ka, with the end of the Younger Dryas glacial relapse, these movements intensified, with the arrival of yet more Southwest Asian lineages. This period also witnessed the expansion of several autochthonous mtDNA lineages across South Asia, in part from sources in the west (possibly carried alongside dispersing Southwest Asian lineages), but primarily from the south. Supporting this view, N e increments at this period are visible in the west and the south, related to the expansion of indigenous M lineages. Disentangling Early Neolithic and Bronze Age dispersals into South Asia After the first settlement, most attention in genetic studies has been focused on the Neolithic and Bronze Age periods, in part due to potential implications for the spread of Indo-European languages. The earliest Neolithic sites, on the Indus Valley around Mehrgarh in Baluchistan, date to before 9 ka [85, 86], and the earliest crops in South Asia derived from Southwest Asian founder crops from the Fertile Crescent [19, 87]. Numerous mtDNA lineages entered South Asia in this period from Anatolia, the Caucasus and Iran. Although some have argued for co-dispersal of the Indo-Aryan languages with the earliest Neolithic from the Fertile Crescent [88, 89], others have argued that, if any language family dispersed with the Neolithic into South Asia, it was more likely to have been the Dravidian family now spoken across much of central and southern India [12]. Moreover, despite a largely imported suite of Near Eastern domesticates, there was also an indigenous component at Mehrgarh, including zebu cattle [85, 86, 90]. The more widely accepted “Steppe hypothesis” [91, 92] for the origins of Indo-European has recently received powerful support from aDNA evidence. Genome-wide, Y-chromosome and mtDNA analyses all suggest Late Neolithic dispersals into Europe, potentially originating amongst Indo-European-speaking Yamnaya pastoralists that arose in the Pontic-Caspian Steppe by ~5 ka, with expansions east and later south into Central Asia in the Bronze Age [53, 76, 93–95]. Given the difficulties with deriving the European Corded Ware directly from the Yamnaya [96], a plausible alternative (yet to be directly tested with genetic evidence) is an earlier Steppe origin amongst Copper Age Khavlyn, Srednij Stog and Skelya pastoralists, ~7-5.5 ka, with an infiltration of southeast European Chalcolithic Tripolye communities ~6.4 ka, giving rise to both the Corded Ware and Yamnaya when it broke up ~5.4 ka [12]. An influx of such migrants into South Asia would likely have contributed to the CHG component in the GW analysis found across the Subcontinent, as this is seen at a high rate amongst samples from the putative Yamnaya source pool and descendant Central Asian Bronze Age groups. Archaeological evidence suggests that Middle Bronze Age Andronovo descendants of the Early Bronze Age horse-based, pastoralist and chariot-using Sintashta culture, located in the grasslands and river valleys to the east of the Southern Ural Mountains and likely speaking a proto-Indo-Iranian language, probably expanded east and south into Central Asia by ~3.8 ka. Andronovo groups, and potentially Sintashta groups before them, are thought to have infiltrated and dominated the soma-using Bactrian Margiana Archaeological Complex (BMAC) in Turkmenistan/northern Afghanistan by 3.5 ka and possibly as early as 4 ka. The BMAC came into contact with the Indus Valley civilisation in Baluchistan from ~4 ka onwards, around the beginning of the Indus Valley decline, with pastoralist dominated groups dispersing further into South Asia by ~3.5 ka, as well as westwards across northern Iran into Syria (which came under the sway of the Indo-Iranian-speaking Mitanni) and Anatolia [12, 95, 97, 98]. Although GW patterns have been broadly argued to support this view [24], there have also been arguments against. For example, Metspalu et al. [28] argued cogently that the GW pattern in South Asia was the result of a complex series of processes, but they also suggested that an East Asian component, common in extant Central Asians, should be evident in the Subcontinent if it had experienced large-scale Bronze Age immigration from Central Asia. In fact, however, aDNA evidence shows that this element was not present in the relevant source regions in the Early Bronze Age [76]. Moreover, whilst the dating and genealogical resolution of Y-chromosome lineages has been weak until recently, it is now clear that a very large fraction of Y-chromosome variation in South Asia has a recent West Eurasian source. |
|
|
|
Post by Admin on Jun 1, 2019 18:22:47 GMT
Genetic signals of Indo-European expansions Contrary to earlier studies [99, 100], recent analyses of Y-chromosome sequence data [55, 58, 94] suggest that haplogroup R1a expanded both west and east across Eurasia during the Late Neolithic/Bronze Age. R1a-M17 (R1a-M198 or R1a1a) accounts for 17.5% of male lineages in Indian data overall, and it displays significantly higher frequencies in Indo-European than in Dravidian speakers [55]. There are now sufficient high-quality Y-chromosome data available (especially Poznik et al. [58]) to be able to draw clear conclusions about the timing and direction of dispersal of R1a (Fig. 5). The indigenous South Asian subclades are too young to signal Early Neolithic dispersals from Iran, and strongly support Bronze Age incursions from Central Asia. The derived R1a-Z93 and the further derived R1a-Z94 subclades harbour the bulk of Central and South Asian R1a lineages [55, 58], as well as including some Russian and European lineages, and have been variously dated to 5.6 [4.0;7.3] ka [55], 4.5–5.3 ka with expansions ~4.0–4.5 ka [58], or 4.7 [4.0;5.5] ka (Yfull tree v4.10 [54]). The South Asian R1a-L657, dated to ~4.2 ka [3.3;5.1] (Yfull tree v4.10 [54]]), is the largest (in the 1KG dataset) of several closely related subclades within R1a-Z94 of very similar time depth. Moreover, not only has R1a been found in all Sintashta and Sintashta-derived Andronovo and Srubnaya remains analysed to date at the genome-wide level (nine in total) [76, 77], and been previously identified in a majority of Andronovo (2/3) and post-Andronovo Iron Age (Tagar and Tachtyk: 6/6) male samples from southern central Siberia tested using microsatellite analysis [101], it has also been identified in other remains across Europe and Central Asia ranging from the Mesolithic up until the Iron Age (Fig. 5). 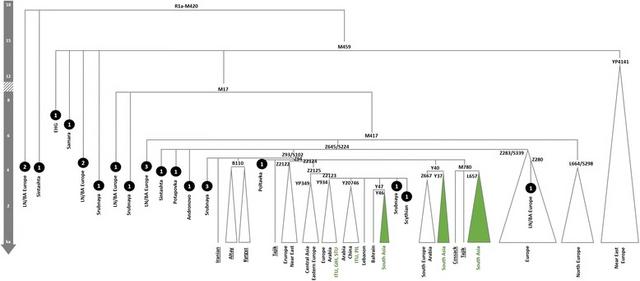 Fig. 5 Schematic tree of Y-chromosome haplogroup R1a. Phylogeny and age estimates based on Yfull tree v4.10 [53]. Age estimates are corroborated by published estimates [54] for some nodes and aDNA evidence from radiocarbon and indirectly dated samples. Underlined samples and/or clades from Karmin et al. 2015 [54]. Black circles represent aDNA samples (number represents the sample size for each culture/period; LN/BA stands for Late Neolithic/Bronze Age) [52, 76, 77] The other major member of haplogroup R in South Asia, R2, shows a strikingly different pattern. It also has deep non-Subcontinental branches, nesting a South Asian specific subclade. But the deep lineages are mainly seen in the eastern part of the Near East, rather than Central Asia or eastern Europe, and the Subcontinental specific subclade is older, dating to ~8 ka [55]. Altogether, therefore, the recently refined Y-chromosome tree strongly suggests that R1a is indeed a highly plausible marker for the long-contested Bronze Age spread of Indo-Aryan speakers into South Asia, although dated aDNA evidence will be needed for a precise estimate of its arrival in various parts of the Subcontinent. aDNA will also be needed to test the hypothesis that there were several streams of Indo-Aryan immigration (each with a different pantheon), for example with the earliest arriving ~3.4 ka and those following the Rigveda several centuries later [12]. Although they are closely related, suggesting they likely spread from a single Central Asian source pool, there do seem to be at least three and probably more R1a founder clades within the Subcontinent [58], consistent with multiple waves of arrival. Genomic Y-chromosome phylogeography is in its infancy compared to mitogenome analysis so it is of course likely that the picture will evolve with sequencing of further South Asian Y-chromosomes, but the picture is already sufficiently clear that we do not expect it to change drastically. Although these migrations appear to have been male-driven, it might nevertheless be possible to detect a minor maternal signal. For example, haplogroup H2b (dating to 6.2 ka [3.8–8.7] ka; Fig. 6) is a starlike subclade with a probable ultimate ancestry in Eastern Europe, but includes several South Asian lineages (from Pakistan, India and Sri Lanka) that probably arrived more recently from Central Asia. Tellingly, H2b also includes two aDNA samples (Fig. 6): one individual from the small number of Yamnaya sampled to date [53, 76] and another from the Late Bronze Age Srubnaya culture [77]. 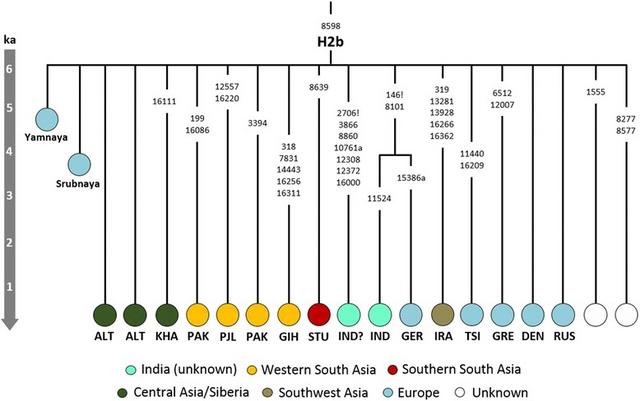 Fig. 6 Tree of mtDNA haplogroup H2b based on ML age estimates for modern sequences. Population codes: ALT—Altai, DEN—Denmark, GER—Germany, GIH—Gujarati Indian from Houston, Texas, GRE—Greece, IND—India (without more details regarding location within India; the sample marked with “?” is possibly Indian), IRA—Iraq, KHA—Khamnigan, PAK—Pakistan, PJL—Punjabi from Lahore, Pakistan, RUS—Russia, TSI—Tuscans from Italy (the Additional file 1: Table S2). The ancient Yamnaya sample has been radiocarbon dated to 3010–2622 calibrated years BCE (Before Common Era) [52]; ancient Srubnaya sample dates to 1850–1600 BCE [77] Even so, the spread of Indo-European within the Subcontinent seems to have been mainly male-mediated, in agreement with recent X-chromosome analyses [102] and as indicated by the high frequency of West Eurasian (mainly R1a) paternal lineages across the region—varying in the 1KG data from ~25% in the northwest and ~20% in the northeast to ~14% in the south, but much more dramatically when taking caste and language into account (from almost 50% in upper-caste Indo-European speakers to almost zero in eastern Austro-Asiatic speakers) [12, 56, 59]. This present-day distribution cannot be directly correlated with language replacement, however, since the signal is also strong in Dravidian-speaking populations (Fig. 3). The last four millennia witnessed major cultural changes in the Indian Subcontinent, with the decline of the Indus Valley civilisation and the rise of Vedic religion, based on a strict caste system, often associated with the arrival of Indo-Aryan speakers. The mix of autochthonous and immigrant genetic lineages seen across South Asia, however, suggests a gradual merging of male-dominated Andronovo/BMAC immigrants with the indigenous descendants of the Indus Valley civilisation [12], possibly associated with the spread of the Megalithic culture as far south as Sri Lanka in the first century Before Common Era (BCE), prior to the establishment of the full jāti caste system very roughly ~2 ka [12, 103]. Basu et al. [26] date the “freezing” of India’s population structure to ~1.5 ka. Although the mtDNA does not suggest similar continent-wide dispersals involving women, the last ~4 ka nevertheless witnessed a profound impact on the demography of maternal lineages, with a population increment associated with the indigenous lineages which might have involved local movements and facilitated the diffusion of the Indo-Aryan languages. This expansion is mainly evident amongst the autochthonous lineages in west and central South Asia. We see no evidence that the caste system emerged in the wake of the arrival of Indo-Aryan speakers from the north, in agreement with formal admixture analyses [24, 26]. Higher-ranking castes do seem closer genetically to Pakistan and ultimately Caucasus and Central Asian populations, but this proximity was most likely established over millennia, by several distinct migratory events—indeed, a sizeable fraction of the non-R1a West Eurasian Y-chromosome lineages (e.g. R2a-M124, J2-M241, L1a-M27, L1c-M357) were most likely associated with the spread of agriculture or even earlier expansions from Southwest Asia, as with the mtDNA lineages [55, 59]. The tribal groups are generally more divergent from other South Asian groups and in particular from western South Asians, but the particular genetic diversity of tribal groups might have been due to isolation [20], and not necessarily because of more recent strict social boundaries enforced by newly-arriving groups imposing a new system, which in its historical form was likely established much more recently, not more than around 2000 years ago [12, 24, 26, 103]. Conclusions The trans-continental demographic impact of the Eurasian Bronze Age In conclusion, analysis of the uniparental marker systems can provide complementary insight into the main genome-wide component that arrived in and spread throughout South Asia since the LGM. This “CHG” component is now known to reach almost 100% in both pre-Neolithic remains from the Caucasus [74] and pre-Neolithic and Early Neolithic remains from Iran [75], and to occur at ~50% in the Pontic-Caspian steppe zone [53, 76], north of the Caucasus, by ~5 ka. This component underwent of multiple dispersals into the Subcontinent, with chronologically distinct sources in the eastern Fertile Crescent and the Steppe, via Central Asia. Moreover, these dispersals involved not simply the spread of early farming from Southwest Asia and the male-dominated arrival of Indo-Aryan speakers from Central Asia. The mtDNA signal suggests several streams of dispersal into the Subcontinent from the northwest since the LGM, and there were also more recent dispersals from the east, with a more limited impact [22]. In some ways, the overall picture for South Asia resembles the settlement history for a much smaller peninsula on the far side of the Near East with a similar sink status—Europe. Europe too was settled by early modern humans in the late Pleistocene, albeit suffering much greater impact from the LGM due to its latitude. Even so, Europe similarly experienced subsequent settlement episodes from the LGM onwards, culminating in the spread of agriculture from Southwest Asia ~9 ka, followed by the similarly male-dominated spread of pastoralism and, most likely, the Indo-European language family in the Late Neolithic/Early Bronze Age from the Pontic-Caspian steppe [65, 76, 77, 84, 104, 105]. Indeed, Y-chromosome haplogroup R1a, which spread with pastoralism and the Indo-European languages into South Asia, also seems to have been carried into Europe a millennium earlier, alongside a similar pastoral economy and language package and its sibling lineage, R1b [53, 58, 76, 94]. Notably, however, the extent to which the R1 lineages replaced earlier Y chromosomes was much greater across Europe than we see in South Asia. This corresponds to the greater impact of Indo-European languages in Europe, which ultimately left few relicts of earlier language families surviving—the only cases still extant being Basque and Finno-Ugric, with Etruscan and Iberian as well-attested but extinct examples. By comparison, almost a quarter of modern Indians speak the Dravidian languages that seem most likely to have been spread by the first farmers [12]. This greater impact in Europe is also reflected in the genome-wide picture. In Europe, although the CHG component is only 10–15% in most populations, it is thought to have been accompanied by a similar fraction of indigenous Mesolithic European lineages from the steppe, seen in Yamnaya samples [53]. This component does not seem to have spread significantly east and south into Central and South Asia, however [76]. Furthermore, in the case of Europe, the major stages are simpler to disentangle from the genome-wide evidence. This is because the distinctiveness of the Levantine source for the Early Neolithic, compared to the Pontic-Caspian steppe, gives most European populations a clear tripartite ancestry that is less evident in South Asia. In fact, even in Europe the situation may be more complex than it first appeared [80, 105, 106]. In the Subcontinent, the Levantine component is (like the European Mesolithic component) minor, due to a deep east–west separation across the Fertile Crescent prior to the spread of the Neolithic [75]. As a result, both the Southwest Asian source for the Late Palaeolithic/Early Holocene and the Steppe/Central Asian source for the Bronze Age largely share the same ancestral pool, which may have arisen in the region of the Caucasus and eastern Fertile Crescent and expanded both north and south during the later Neolithic and Early Bronze Age [74, 75, 95]. Consequently, it may be that only a minor fraction of the CHG component represents Indo-Aryan arrivals in South Asia, perhaps helping to explain why Metspalu et al. [28] were unable to detect it. In any case, estimates of the putative ancestral contributions in clustering analyses such as ADMIXTURE vary considerably depending on the data used, as well as being confounded by other factors such as bottlenecks and unsampled source regions, and so need to be treated with considerable caution [107, 108]. BMC Evol Biol. 2017; 17: 88. Published online 2017 Mar 23. |
|
|
|
Post by Admin on Aug 23, 2019 18:58:52 GMT
Abstract Situated at over 5,000 meters above sea level in the Himalayan Mountains, Roopkund Lake is home to the scattered skeletal remains of several hundred individuals of unknown origin. We report genome-wide ancient DNA for 38 skeletons from Roopkund Lake, and find that they cluster into three distinct groups. A group of 23 individuals have ancestry that falls within the range of variation of present-day South Asians. A further 14 have ancestry typical of the eastern Mediterranean. We also identify one individual with Southeast Asian-related ancestry. Radiocarbon dating indicates that these remains were not deposited simultaneously. Instead, all of the individuals with South Asian-related ancestry date to ~800 CE (but with evidence of being deposited in more than one event), while all other individuals date to ~1800 CE. These differences are also reflected in stable isotope measurements, which reveal a distinct dietary profile for the two main groups.  Nestled deep in the Himalayan mountains at 5029 m above sea level, Roopkund Lake is a small body of water (~40 m in diameter) that is colloquially referred to as Skeleton Lake due to the remains of several hundred ancient humans scattered around its shores (Fig. 1)1. Little is known about the origin of these skeletons, as they have never been subjected to systematic anthropological or archaeological scrutiny, in part due to the disturbed nature of the site, which is frequently affected by rockslides2, and which is often visited by local pilgrims and hikers who have manipulated the skeletons and removed many of the artifacts3. There have been multiple proposals to explain the origins of these skeletons. Local folklore describes a pilgrimage to the nearby shrine of the mountain goddess, Nanda Devi, undertaken by a king and queen and their many attendants, who—due to their inappropriate, celebratory behavior—were struck down by the wrath of Nanda Devi4. It has also been suggested that these are the remains of an army or group of merchants who were caught in a storm. Finally, it has been suggested that they were the victims of an epidemic5.  Fig. 1 Context of Roopkund Lake. a Map showing the location of Roopkund Lake. The approximate route of the Nanda Devi Raj Jat pilgrimage relative to Roopkund Lake is shown in the inset. b Image of disarticulated skeletal elements scattered around the Roopkund Lake site. Photo by Himadri Sinha Roy. c Image of Roopkund Lake and surrounding mountains. Photo by Atish Waghwase To shed light on the origin of the skeletons of Roopkund, we analyzed their remains using a series of bioarcheological analyses, including ancient DNA, stable isotope dietary reconstruction, radiocarbon dating, and osteological analysis. We find that the Roopkund skeletons belong to three genetically distinct groups that were deposited during multiple events, separated in time by approximately 1000 years. These findings refute previous suggestions that the skeletons of Roopkund Lake were deposited in a single catastrophic event. |
|
|
|
Post by Admin on Aug 24, 2019 18:38:58 GMT
Bioarcheological analysis of the Roopkund skeletons
We obtained genome-wide data from 38 individuals by extracting DNA from powder drilled from long bones, producing next-generation sequencing libraries, and enriching them for approximately 1.2 million single nucleotide polymorphisms (SNPs) from across the genome6,7,8,9, obtaining an average coverage of 0.51 × at targeted positions (Table 1, Supplementary Data 1). We also obtained PCR-based mitochondrial haplogroup determinations for 71 individuals (35 of these were ones for whom we also obtained genome-wide data that confirmed the PCR-based determinations) (Table 2, Supplementary Note 1). We generated stable isotope measurements (δ13C and δ15N) from 45 individuals, including 37 for whom we obtained genome-wide genetic data, and we obtained direct radiocarbon dates for 37 individuals for whom we also had both genetic and isotope data (Table 1).
Table 1 Information on 38 individuals with genome-wide data
From: Ancient DNA from the skeletons of Roopkund Lake reveals Mediterranean migrants in India
Sample ID Skeletal codes No. libraries produced Population label Sex Mitochondrial DNA haplogroup (based on Sequenom genotyping) Mitochondrial DNA haplogroup (based on mt capture) Y-chromosome haplogroup Proportion of endogenous human DNA before capture (best library) 1240k coverage (average) No. of SNPs hit on autosomes C-to-T damage rate at terminal bases (average) X-chromosome contamination point estimate (for males with > 200 SNPs) Mitochondrial DNA match rate to consensus sequence Calibrated radiocarbon datesc δ13C (‰)d δ15N (‰)d
I2868 R01 3 Roopkund_A M M1a1c M33d H1a2a1 0.014 0.868 570995 0.071 .. 0.996 890–982 CE −19.40 −7.69
I2871 R04 4 Roopkund_A F M3C1 M3c1a .. 0.005 0.579 441880 0.049 .. 0.997 773–940 CE −16.32 −9.77
I2872 R06 4 Roopkund_A F M3c2 M3c2 .. 0.003 0.199 196393 0.046 .. 1.000 773–940 CE −19.00 −9.24
I3342 R08 1 Roopkund_A M M3a2 M3a2 H1a1d2 0.007 0.577 403739 0.047 0.013 1.000 773–940 CE −18.94 (−18.88) −9.69 (−9.85)
I3343 R10 1 Roopkund_A F M3 M3 .. 0.006 0.223 203058 0.055 .. 1.000 773–890 CE −19.74 −9.99
I3344 R11 1 Roopkund_A F U U2c1 .. 0.003 0.105 111184 0.049 .. 1.000 775–890 CE −11.45 −8.71
I3346 R15 1 Roopkund_A M .. M30c E1b1b1 0.004 0.304 271560 0.065 0.008 1.000 717–889 CE −15.93 −10.29
I3349 R17 1 Roopkund_A F .. M5a .. 0.004 0.133 136268 0.059 .. 0.998 770–945 CE −10.74 −9.58
I3351 R19 1 Roopkund_A M M3a1 M4 Jb 0.006 0.044 50278 0.057 .. 0.994 770–887 CE −14.47 (−14.42) −9.39 (−9.63)
I3352 R20 1 Roopkund_A M HV HV14 R2a3a2b2c 0.017 1.476 591844 0.041 0.004 0.998 689–876 CE −16.27 −9.13
I3402 R25 1 Roopkund_A M M5a U1a1a H3b 0.002 0.118 125762 0.036 .. 1.000 770–887 CE −17.18 −10.36
I3406 R43 1 Roopkund_A M M30 M30 J2a1 0.016 0.295 251527 0.045 .. 0.999 885–980 CE −18.46 (−18.07) 7.95 (−8.23)
I3407 R44 1 Roopkund_A M M3a1 M3a1 H1a1d2 0.011 0.105 110441 0.045 .. 0.976 775–961 CE −18.22 (−18.27) −9.85 (−9.69)
I6934 R45 1 Roopkund_A F .. .. .. 0.034 0.861 521678 0.033 .. 1.000 773–890 CE −16.53 −8.41
I6938 R51 1 Roopkund_A F X X2p .. 0.011 0.481 405124 0.058 .. 0.999 694–875 CE −18.62 (−18.16) −8.25 (−8.4)
I6941 R55 1 Roopkund_A M J1b1a1 J1b1a1 .. 0.009 0.590 452228 0.044 −0.001 1.000 894–985 CE −10.13 −8.90
I6942 R57 1 Roopkund_A M P4b1 R30b2a .. 0.008 0.602 470065 0.047 −0.001 1.000 770–887 CE −18.66 (−18.42) −8.22 (−8.33)
I6943 R61 1 Roopkund_A M M3a1 M3a1 .. 0.007 0.133 145489 0.064 .. 0.999 675–769 CE −10.10 −8.24
I6944 R62 1 Roopkund_A F U2e3 U4d3 .. 0.009 0.340 313369 0.055 .. 1.000 726–885 CE −18.00 (−18.10) −8.58 (−7.9)
I6945 R64 1 Roopkund_A F M4″67 M30 + 16234 .. 0.007 0.035 40150 0.045 .. 0.997 687–870 CE −17.08 −8.92
I6946 R65 1 Roopkund_A M U2a1 U8b1a1 .. 0.005 0.349 328001 0.055 −0.002 1.000 773–890 CE −10.21 −10.09
I7035 R68 1 Roopkund_A F U7 U7a2 .. 0.008 0.565 446699 0.041 .. 0.999 889–971 CE −16.74 (−16.50) −10.19 (−10.21)
I7036 R69 1 Roopkund_A M H H13a2a .. 0.009 0.370 342426 0.057 0.005 1.000 778–988 CE −18.59 −9.33
I2869 R02 4 Roopkund_B M H H6b1 J1a3a 0.036 0.782 578890 0.057 .. 0.997 1668–1945 CE −18.69 −10.89
I2870 R03 2 Roopkund_B F T1 T1a .. 0.024 0.028 31880 0.039 .. 0.938 1706–1915 CE −18.67 −11.15
I3345 R13 1 Roopkund_B M H1 H1 R1a1a1b1a2b 0.056 1.547 706651 0.059 0.002 0.997 1681–1939 CE −18.93 −10.76
I3348 R16 1 Roopkund_B F H1 H1c .. 0.006 0.409 352584 0.051 .. 1.000 1682–1932 CE −19.23 −9.21
I3350 R18 1 Roopkund_B M H H60a G2a2b2a1a1c1a2 0.031 1.349 614489 0.069 0.004 0.995 1675–1943 CE −19.41 (−19.10) −9.95 (−10.02)
I3401 R22 1 Roopkund_B M N2 W1 R1b1ab 0.005 0.049 56291 0.056 .. 1.000 .. .. ..
I3403 R39 1 Roopkund_B M N X2d T1a2 0.018 0.492 379935 0.035 0.005 0.995 1691–1925 CE −18.60 (−18.19) −10.77 (−10.61)
I3404 R40 1 Roopkund_B M H H12 E1b1b1b2 0.040 1.077 541763 0.041 0.006 0.997 1706–1915 CE −19.23 −9.62
I3405 R42 1 Roopkund_B F J1b J1b .. 0.019 0.514 346216 0.031 .. 1.000 1656-… CE −19.72 −10.07
I6935 R46 1 Roopkund_B F HV .. .. 0.017 0.627 524922 0.060 .. 0.997 1668–1945 CE −18.97 −8.91
I6936 R48 1 Roopkund_B M M2a1a H1b .. 0.034 1.371 728448 0.043 0.005 0.998 1681–1939 CE −18.79 −9.79
I6937 R49 1 Roopkund_B F H12 H12a .. 0.026 0.837 584656 0.035 .. 1.000 1661-… CE −19.56 −8.93
I6939 R53 1 Roopkund_B M H1 H1 .. 0.008 0.605 476797 0.037 0.006 0.999 1680–1939 CE −19.22 −10.46
I6947 R66 1 Roopkund_B M K K1a .. 0.050 0.026 30592 0.025 .. 0.940 1675–1943 CE −18.95 −9.96
I6940 R54 1 Roopkund_C M M24 M24a O1b1a1a1b 0.011 0.489 419098 0.047 0.022 1.000 1653-… CE −19.25 (−18.32) −9.98 (−9.74)
Mitochondrial DNA haplogroups that are inconsistent between the capture and PCR-based methods are indicated
In this study, we also present an osteological assessment of health and stature performed on a different set of bones from Roopkund; this report was drafted well before genetic results from Roopkund were available but was never formally published (an edited version of the original report is presented here as Supplementary Note 2). The analysis suggests that the Roopkund individuals were broadly healthy, but also identifies three individuals with unhealed compression fractures; the report hypothesizes that these injuries could have transpired during a violent hailstorm of the type that sometimes occurs in the vicinity of Roopkund Lake, while also recognizing that other scenarios are plausible. The report also identifies the presence of both very robust and tall individuals (outside the range of almost all South Asians), and more gracile individuals, and hypothesizes based on this the presence of at least two distinct groups of individuals, consistent with our genetic findings (Supplementary Note 2).
Our analysis of the genome-wide data from 38 Roopkund individuals shows that they include both genetic males (n = 23) and females (n = 15)—consistent with the physical anthropology evidence for the presence of both males and females (Supplementary Note 2). The relatively similar proportions of males and females is difficult to reconcile with the suggestion that these individuals might have been part of a military expedition. We detected no relative pairs (3rd degree or closer) among the sequenced individuals10, providing evidence against the idea that the Roopkund skeletons might represent the remains of groups of families. We also found no evidence that the individuals were infected with bacterial pathogens, providing no support for the suggestion that these individuals died in an epidemic, although we caution that failure to find evidence for pathogen DNA in long bone powder may simply reflect the fact that it was present at too low a concentration to detect (Supplementary Note 3)11.
Table 2 Mitochondrial DNA haplogroup determination for 71 individuals
From: Ancient DNA from the skeletons of Roopkund Lake reveals Mediterranean migrants in India
Skeletal codes mt-DNA haplogroup (determined via multiplex PCR analysis) Mutational differences from rCRS (determined via multiplex PCR analysis) Whole-genome ID mt-DNA haplogroup (determined via whole-genome sequencing) Population label (determined via whole-genome sequencing)
R01 M1a1c 15043, 3384, 7094, 11215 I2868 M33d Roopkund_A
R02 H 2706, 12705, 11719, 14766, 16223 I2869 H6b1 Roopkund_B
R03 T1 16294, 16223, 12633, 11251, 15452, 8701, 15607, 1888, 14905, 11215, 9540, 8697, 16126, 12633, 4216, 709 I2870 T1a Roopkund_B
R04 M3C1 15043, 482, 16294 I2871 M3c1a Roopkund_A
R05 M2c 15043, 4216 .. .. ..
R06 M3c2 15043, 16126, 482 I2872 M3c2 Roopkund_A
R07 U4b2 11467, 8701 .. .. ..
R08 M3a2 15043, 16126, 482, 5783, 10727 I3342 M3a2 Roopkund_A
R09 U2b2 1888, 11467, 12308, 2706, 12705, 8701, 1811 .. .. ..
R10 M3 15043, 16126 I3343 M3 Roopkund_A
R11 U 11467, 12308, 8701, 3714, 13188 I3344 U2c1 Roopkund_A
R12 M4″67 12007, 15043 .. .. ..
R13 H1 16223, 14766, 11719, 12705, 9540, 3010, 2706 I3345 H1 Roopkund_B
R14 N1b 9540, 8701, 1598 .. .. ..
R15 .. .. I3346 M30c Roopkund_A
R16 H1 16223, 11719, 5301, 3434, 12705, 9540, 3010, 2706 I3348 H1c Roopkund_B
R17 .. 16223, 14766, 11719, 8701, 12705, 9540, 2706 I3349 M5a Roopkund_A
R18 H 15043, 482, 4703 I3350 H60a Roopkund_B
R19 M3a1 9540, 12705, 8701, 11719, 14766, 16223 I3351 M4 Roopkund_A
R20 HV 9540, 12705, 8701, 11719, 14766, 16223 I3352 HV14 Roopkund_A
R21 HV 709, 16126, 207, 9540, 8701 .. .. ..
R22 N2 8701, 11719, 14766, 16223 I3401 W1 Roopkund_B
R23 HV 15043, 9540, 8701, 12361 .. .. ..
R24 N1a1b1 1888, 15043, 7094, 7859, 11215, 8701, 16172, 13104, 16223 .. .. ..
R25 M5a 709, 11083, 15043, 8502, 16274, 12810 I3402 U1a1a Roopkund_A
R26 M2a 709, 1888, 15043 .. .. ..
R28 M5 9540, 12705, 8701, 16223 .. .. ..
R29 R2 15043, 16126, 5301 .. .. ..
R31 M6 1888, 15043 .. .. ..
R32 M5 15043 .. .. ..
R33 M 12007, 15043, 5301, 3714, 13104, 16223, 16294 .. .. ..
R34 M4″67 1888, 11467, 12308, 2706, 9540, 12705, 8701, 1811 .. .. ..
R35 U2b 15043 .. .. ..
R36 M9a2 16126, 9540, 12705, 8701, 1811, 16223 .. .. ..
R37 HV 11467, 12308, 9540, 12705, 8701, 1811, 16223 .. .. ..
R38 U2e 6221, 6371, 9540, 8701 .. .. ..
R39 N 2706, 9540, 12705, 8701, 11719, 14766, 16223 I3403 X2d Roopkund_B
R40 H 2706, 9540, 12705 I3404 H12 Roopkund_B
R41 T1 16223, 14766, 11719, 8701, 12705, 9540, 2706, 16126, 15043, 4491 .. .. ..
R42 J1b 709, 1888, 4216, 12633, 16126, 8697, 9540, 14905, 15607, 8701, 15452, 11251, 12633, 16223 I3405 J1b Roopkund_B
R43 M30 4216, 16126, 3010, 9540, 16612, 12705, 8701, 12406, 15452, 16069, 11251, 16223 I3406 M30 Roopkund_A
R44 M3a1 12007, 15043 I3407 M3a1 Roopkund_A
R45 .. .. I6934 .. Roopkund_A
R46 HV 15043, 16126, 482, 4703 I6935 .. Roopkund_B
R47 H 2706, 9540, 12705, 8701, 11719, 14766 .. .. ..
R48 M2a1a 15670, 207, 4703 I6936 H1a Roopkund_B
R49 H12 2706, 9540, 12705, 16223 I6937 H12a Roopkund_B
R50 U4 11467, 12308 .. .. ..
R51 X 6221, 9540, 8701 I6938 X2p Roopkund_A
R52 M6 15043, 5082, 5301 .. .. ..
R53 H1 2706, 3010, 9540, 12705, 8701, 11719, 14766, 16223 I6939 H1 Roopkund_B
R54 M24 15043, 13359, 15607 I6940 M24a Roopkund_C
R55 J1b1a1 4216, 12007, 16126, 3010, 9540, 12612, 12705, 8701, 15452, 16069, 16172, 11251, 16223 I6941 J1b1a1 Roopkund_A
R56 M 15043 .. .. ..
R57 P4b1 12007, 15043 I6942 R30b2a Roopkund_A
R59 D4 15043, 3010, 5178, 8414 .. .. ..
R60 M4″67 12007, 15043 .. .. ..
R61 M3a1 15043, 16126, 482, 4703 I6943 M3a1 Roopkund_A
R62 U2e3 16223, 1811, 8701, 12705, 9540, 12308, 11467 I6944 U4d3 Roopkund_A
R63 U2e3 11467, 12308, 9540, 12705, 8701, 1811, 16223 .. .. ..
R64 M4″67 12007, 15043 I6945 M30 + 16234 Roopkund_A
R65 U2a1 11467, 12308, 9540, 12705, 8701, 10609, 1811, 16223 I6946 U8b1a1 Roopkund_A
R66 K 11467, 12308, 8701, 1811, 16223 I6947 K1a Roopkund_B
R67 M 15043 .. .. ..
R68 U7 11467, 12308, 9540, 12705, 8701, 14569, 1811, 16223 I7035 U7a2 Roopkund_A
R69 H 709, 2706, 9540, 12705, 8701, 11719, 14766, 16223 I7036 H13a2a Roopkund_A
R72 T 4216, 16126, 9540, 12705, 8701, 16223 .. .. ..
R73 U 3741, 12308, 11467 .. .. ..
R74 U 11467, 12308 .. .. ..
R76 JT 16126, 12308 .. .. ..
R77 U 11467, 12308 .. .. ..
Denotes cases where mitochondrial DNA haplogroup determination differs substantially between the multiplex-PCR-based method and mitochondrial capture based analysis
|
|
|
|
Post by Admin on Aug 25, 2019 18:03:12 GMT
Roopkund skeletons form three genetically distinct groups We explored the genetic diversity of the 38 Roopkund individuals using a previously established Principal Component Analysis (PCA) that is effective at visualizing genetic variation of diverse present-day people from South Asia (a term we use to refer to the territories of the present day countries of India, Pakistan, Nepal, Bhutan, Bangladesh, and Bhutan) relative to West Eurasian-related groups (a term we use to refer to the cluster of ancestry types common in Europe, the Near East, and Iran) and East Asian-related groups (a term we apply to the cluster of ancestry types common in East Asia including China, Japan, Southeast Asia, and western Indonesia)12. We find that the Roopkund individuals cluster into three distinct groups, which we will henceforth refer to as Roopkund_A, Roopkund_B, and Roopkund_C (Fig. 2a). Individuals in Roopkund_A (n = 23) fall along a genetic gradient that includes most present-day South Asians. However, they do not fall in a tight cluster along this gradient, suggesting that they do not comprise a single endogamous group, and instead derive from a diversity of groups. Individuals belonging to the Roopkund_B cluster (n = 14) do not fall along this gradient, and instead fall near present-day West Eurasians, suggesting that Roopkund_B individuals possess West Eurasian-related ancestry. A single individual, Roopkund_C, falls far from all other Roopkund individuals in the PCA, between the Onge (Andaman Islands) and Han Chinese, suggesting East Asian-related ancestry. 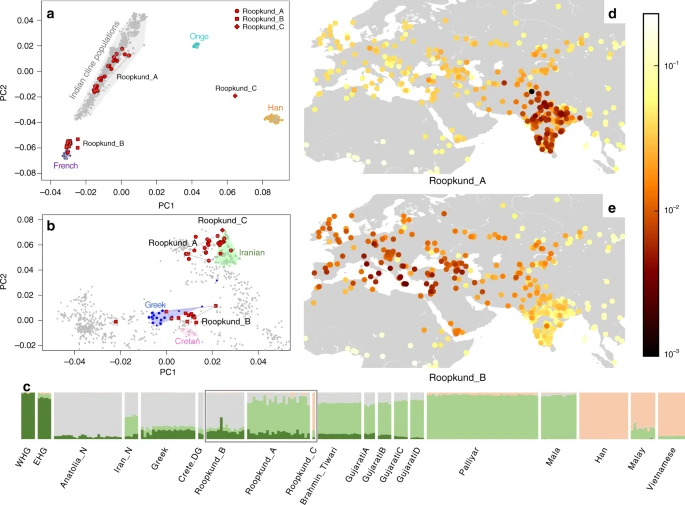 Fig. 2 Genetic Structure of the Skeletons of Roopkund Lake. a Principal component analysis (PCA) of 1,453 present day individuals from selected groups throughout mainland South Asia (highlighted in gray). French individuals (representing the location where West Eurasian populations are known to cluster) are shown in purple, Chinese individuals are shown (representing the location where East Asian populations are known to cluster) in orange, and Andamanese individuals are shown in teal; the 38 Roopkund individuals are projected. b PCA of 988 present day West Eurasians with the Roopkund individuals projected. The PCA plot is truncated to remove Sardinians and southern Levantine groups; Present-day Greeks are shown in blue, Cretans in pink, Iranians in green, and all other West Eurasian populations in gray. A gray polygon encloses all the individuals in each Roopkund group with > 100,000 SNPs. c ADMIXTURE analysis of 2344 present-day and 1877 ancient individuals with K = 4 ancestral components. Only a subset of individuals with ancestries relevant to the interpretation of the Roopkund individuals are shown. Consistent with the PCA, Roopkund_A has ancestry most closely matching Indian groups; Roopkund_B has ancestry most closely matching Greek and Cretan groups; and Roopkund_C has ancestry most closely matching Southeast Asian groups. Genetic differentiation (FST) between Roopkund_A (d) and diverse present-day populations, and Roopkund_B (e) and diverse present-day populations. We only plotted present-day populations for which we have latitudes and longitudes; deeper red coloration indicates less differentiation to the Roopkund genetic cluster being analyzed. To further understand the West Eurasian-related affinity in the Roopkund_B cluster, we projected all the Roopkund individuals onto a second PCA designed to distinguish between sub-components of West Eurasian-related ancestry13,14 (Fig. 2b). Individuals assigned to the Roopkund_A and Roopkund_C groups cluster towards the top right of the PCA plot, close to present-day groups with Iranian ancestry, consistent with where populations with South Asian or East Asian ancestry cluster when projected onto such a plot13. Individuals belonging to the Roopkund_B group cluster toward the center of the plot, close to present-day people from mainland Greece and Crete15. We observe consistent patterns using the automated clustering software ADMIXTURE16 (Fig. 2c) and in pairwise FST statistics (Fig. 2d, e, Supplementary Data 2). The visual evidence from the PCA suggests that two individuals from the Roopkund_B group might represent genetic outliers (Fig. 2b). However, symmetry f4-statistics show that the two apparent outliers (one of which has relatively low coverage) are statistically indistinguishable in ancestry from individuals of the main Roopkund_B cluster relative to diverse comparison populations (Supplementary Data 3), and so we lump all the Roopkund_B individuals together in what follows. Skeletons at Roopkund Lake were deposited in multiple events The discovery of multiple, genetically distinct groups among the skeletons of Roopkund Lake raises the question of whether these individuals died simultaneously or during separate events. We used Accelerator Mass Spectrometry (AMS) radiocarbon dating to determine the age of the remains. We successfully generated radiocarbon dates from all but one of the individuals for which we have genetic data, using the same stocks of bone powder that we used for genetic analysis to ensure that the dates correspond directly to the genetic groupings. We find that the Roopkund_A and Roopkund_B groups are separated in time by ~1000 years, with the calibrated dates for individuals assigned to the Roopkund_A group ranging from the 7th–10th centuries CE, and the calibrated dates for individuals assigned to the Roopkund_B group ranging from the 17th–20th centuries CE (Table 1; Fig. 3a; Supplementary Data 4). The single individual assigned to Roopkund_C also dates to this later period. These results demonstrate that the skeletons of Roopkund Lake perished in at least two separate events. For Roopkund_A, we detect non-overlapping 95% confidence intervals (for example individual I6943 dates to 675–769 CE, while individual I6941 dates to 894–985 CE), suggesting that even these individuals may not have died simultaneously (Fig. 3a). In contrast, the calibrated dates obtained for 13 Roopkund_B individuals and the single Roopkund_C individual all have mutually overlapping 95% confidence intervals. 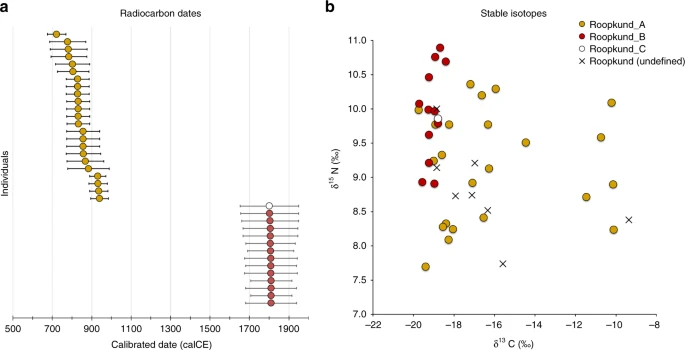 Fig. 3 Radiocarbon and Isotopic Evidence of Distinct Origins of Roopkund Genetic Groups. a We generated 37 accelerator mass spectrometry radiocarbon dates and calibrated them using OxCal v4.3.2. The dating reveals that the individuals were deposited in at least two events ~1000 years apart. In fact, the Roopkund_A individuals (shown in yellow) may have been deposited over an extended period themselves, as the 95% confidence intervals for some of the radiocarbon dates (for example I6943 and I6941) do not overlap. Radiocarbon dates indicate that Roopkund_B (shown in red) and Roopkund_C (shown in white) individuals may have been deposited during a single event. Error bars indicate 95.4% confidence intervals. Calibration curves are shown in Supplementary Fig. 1. b We show normalized δ13C and δ15N values for samples with isotopic data: 37 for which genetic data were generated (circles with colors indicating their cluster), and eight for which no genetic data were generated (labeled Roopkund_U). In cases where multiple measurements were obtained, we plot the average of all measurements. Differences in diet correlate with genetic groupings We carried out carbon and nitrogen isotope analysis of femur bone collagen for 45 individuals. Femur bone collagen is determined by diet in the last 10–20 years of life17, and therefore is not necessarily correlated with the genetic ancestry of a population, which reflects processes occurring over generations. Nevertheless, we find evidence of dietary heterogeneity across the genetic ancestry groupings, providing additional support for the presence of multiple distinct groups at Roopkund Lake. We first observed that the Roopkund individuals are characterized by a range of δ13C values indicating diets reliant on both C3 and C4 plant sources, as well as δ15N values indicating varying degrees of consumption of protein derived from terrestrial animals (Fig. 3b and Supplementary Note 4). The δ13C values are non-randomly associated with the genetic groupings for the 37 individuals for whom we had both measurements. We find that all the Roopkund_B individuals (with typically eastern Mediterranean ancestry), as well as the Roopkund_C individual, have δ13C values between −19.7‰ and −18.2‰ reflecting consumption of terrestrial C3 plants, such as wheat, barley, and rice (and/or animals foddered on such plants). In contrast, the Roopkund_A individuals (with typically South Asian ancestry) have much more varied δ13C values (−18.9‰ to −10.1‰), with some implying C3 plant reliance and others reflecting either a mixed C3 and C4 derived diet, or alternatively consumption of C3 plants along with animals foddered with millet, a C4 plant (a practice that has been documented ethnographically in South Asia17). The difference in the δ13C distribution between the Roopkund_A and Roopkund_B groupings is highly significant (p = 0.00022 from a two-sided Mann-Whitney test). Genetic affinities of the Roopkund subgroups We used qpWave18,19 to test whether Roopkund_B is consistent with forming a genetic clade with any present-day population (that is, whether it is possible to model the two populations as descending entirely from the same ancestral population with no mixture with other groups since their split). We selected 26 present-day populations for comparison, with particular emphasis on West Eurasian-related groups (we analyzed the West Eurasian-related groups Basque, Crete, Cypriot, Egyptian, English, Estonian, Finnish, French, Georgian, German, Greek, Hungarian, Italian_North, Italian_South, Norwegian, Spanish, Syrian, Ukranian, and the non-West-Eurasian-related groups Brahmin_Tiwari, Chukchi, Han, Karitiana, Mala, Mbuti, Onge, and Papuan). We find that Roopkund_B is consistent with forming a genetic clade only with individuals from present-day Crete. These results by no means imply that the Roopkund_B individuals originated in the island of Crete itself, although they suggest that their recent ancestors or they themselves came from a nearby region (Supplementary Note 5; Supplementary Data 5). We performed a similar analysis on individuals belonging to the Roopkund_A group and find that they cannot be modeled as deriving from a homogeneous group (Supplementary Note 6). Instead, Roopkund_A individuals vary significantly in their relationship to a diverse set of present-day South Asians, consistent with the heterogeneity evident in PCA (Fig. 2a). We were unable to model the Roopkund_C individual as a genetic clade with any present-day populations, but we were able to model its ancestry as ~82% Malay-related and ~18% Vietnamese-related using qpAdm7, showing that this individual is consistent with being of Southeast Asian origin. We tested if any of the Roopkund groups show specific genetic affinity to present-day groups from the Himalayan region, including four neighboring villages in the northern Ladakh region for which we report new genome-wide sequence data, but we find no such evidence (Supplementary Note 7). Within the Roopkund_A group which has ancestry that falls within the variation of present-day South Asians, we observe a weakly significant difference in the proportion of West Eurasian-related ancestry in males and females (p = 0.015 by a permutation test across individuals; Supplementary Note 8), with systematically lower proportions of West Eurasian-related ancestry in males than females. This suggests that the males and females were drawn from significantly different mixtures of groups within South Asia. |
|

